这篇是我自己学 Ray 边用边记的笔记,假设你刚接触分布式但写过 Python。先从 Ray 的底层架构讲起,再讲它在金融建模中的应用场景,最后手把手用 Ray 训练一个完整的 LightGBM 因子模型。看完你应该能明白:Ray 到底在帮你做什么、为什么能加速、以及怎么用。
一、为什么金融模型训练需要 Ray?
1.1 一个常见的痛苦场景
先讲一个量化研究里非常具体的痛苦场景。
你是个量化研究员,手里有 10 年的分钟级股票数据(大约 200GB),要做一个选股模型。流程大概是这样的:
- 特征工程:对每只股票算 200+ 个因子(动量、波动率、换手率、技术指标 ……)
- 参数调优:LightGBM 有十几个超参数,要做网格搜索,组合数轻松破千
- 滚动回测:每个参数组合都要在 10 年时间窗上滚动训练 + 预测
- 多模型集成:行业中性、市值中性 …… 不同口径要分别跑
如果用单机 Python 串行跑完,按经验大概要 3 天。等结果出来,市场早就变了。
graph LR
A[单机 Python 串行] -->|3天| B[结果]
C[Ray 分布式 32核] -->|2小时| D[结果]
style A fill:#fbb,stroke:#c00
style C fill:#bfb,stroke:#0a0
Ray 解决的就是这个问题:让你用几乎不修改的 Python 代码,把单机程序变成分布式程序,把 3 天压到 2 小时。
1.2 一个我刚跑过的真实例子
上面这个场景听起来还有点抽象,我给你一个我这两天在自己 Mac 上实测的真例子。
我手头有个开源项目叫 Kronos——一个面向 K 线的金融 Foundation Model。它在生成完 30 个蒙特卡洛预测样本之后,需要训练一个 LightGBM Meta 模型 来过滤"该不该开仓"的信号。完整流程是:
- 从 573 个 parquet 文件(15GB,每个文件一天 5min K 线 + 30 组 MC 预测)抽取信号特征和市场特征
- 用 Triple Barrier 算法打标签
- 24 组超参 × 3 折 CV = 72 次 LightGBM 训练,选最优配置
按 50 文件子集外推,串行跑一遍要约 3.8 小时。我用 Ray 改完之后,在 M2 Pro / 10 核 / 32GB 的笔记本上 跑完只要约 20 分钟,加速比 ~12x:
| 阶段 | 串行耗时 | Ray 并行 | 加速比 |
|---|---|---|---|
| 特征抽取(50 文件 × 288 行) | 85.69s | 26.28s | 3.26x |
| 24 组超参 × 3 折 LightGBM Tune | 1128.99s | 74.66s | 15.12x |
| 端到端 | ~20 min | ~1.7 min | ~12x |
最优 AUC = 0.6672(50 文件子集 + 合成标签 + 普通 KFold,仅做演示)。完整的代码、Ray Tune 的输出截图、踩过的坑、以及"模型到底能不能用"的判断标准,都在 第六章 里。
这就是 Ray 在量化研究里最实际的价值:本身不会让你的模型变好,但能把"晚上挂机跑明早看"压成"喝杯咖啡看一眼「可惜现在喝不了咖啡了😭」",单位时间里能试错的次数翻 10 倍。
但在用之前,必须先搞懂它的底层是怎么工作的,否则一定会踩坑。
二、Ray 的底层架构
2.1 Ray 是什么?
一句话定义:Ray 是一个通用的分布式计算框架,把"函数调用"和"对象引用"这两个 Python 程序员最熟悉的概念,扩展到了多机环境。
它不像 Spark 那样强制你用 DataFrame,也不像 MPI 那样要写一堆通信代码。你只要在普通函数上加一个装饰器,它就能跑在几百台机器上。
Ray 的核心 thesis:用一个通用底层代替一堆专用系统
ML 在过去十几年里跑出了一大批"各管一段"的分布式系统:
graph TB
subgraph "ML 全生命周期"
Data[数据处理
Spark / Hadoop / Flink]
Train[模型训练
Horovod / DistTF / Parameter Server]
Hyper[超参搜索
Vizier / 各厂内部系统]
Sim[强化学习
RLlib / Baselines / Coach]
Serve[在线推理
Clipper / TF Serving]
Stream[流处理
Flink / Kafka Streams]
end
Data -.->|换一套系统| Train
Train -.->|又换一套| Hyper
Hyper -.->|又换一套| Sim
Sim -.->|又换一套| Serve
style Data fill:#fed
style Train fill:#fed
style Hyper fill:#fed
style Sim fill:#fed
style Serve fill:#fed
style Stream fill:#fed
每个虚线箭头都是一次"换轨道":换 API、换部署、换运维、换调试工具。Ray 的立论是把这些 specialized systems 替换成一个 general-purpose 系统 + 一层薄薄的库:
graph TB
subgraph "Ray 范式"
Core[Ray 核心
Task / Actor / Object]
D2[ray.data]
T2[ray.train]
TUN[ray.tune]
S2[ray.serve]
RLL[RLlib]
end
Core --> D2
Core --> T2
Core --> TUN
Core --> S2
Core --> RLL
style Core fill:#dfe,stroke:#0a0,stroke-width:2px
底层只有 Task(函数)+ Actor(类)+ Object(共享数据) 三件事,上层各种库都是这三件事的不同组合。这就是为什么本文一会儿用 @ray.remote、一会儿用 ray.tune、一会儿讲 ray.data——它们底下其实是同一套调度器和对象存储,不像 Spark→Horovod 那样真要换栈。
2.2 整体架构图
graph TB
subgraph "Ray 集群"
subgraph "Head Node 头节点"
GCS[GCS
全局控制服务]
Driver[Driver
你的主程序]
HeadRaylet[Raylet]
end
subgraph "Worker Node 1 工作节点"
R1[Raylet
本地调度器]
OS1[Object Store
共享内存]
W1A[Worker A]
W1B[Worker B]
end
subgraph "Worker Node 2 工作节点"
R2[Raylet
本地调度器]
OS2[Object Store
共享内存]
W2A[Worker A]
W2B[Worker B]
end
GCS <-->|心跳/元数据| R1
GCS <-->|心跳/元数据| R2
Driver -->|提交任务| HeadRaylet
R1 <-->|任务/对象转移| R2
OS1 <-.->|跨节点拉取| OS2
end
style GCS fill:#ffd,stroke:#c90
style OS1 fill:#dfd,stroke:#090
style OS2 fill:#dfd,stroke:#090
四个核心组件:
| 组件 | 作用 | 类比 |
|---|---|---|
| GCS(Global Control Service) | 存储集群元数据、Actor 位置、调度状态 | 类似 K8s 里的 etcd |
| Raylet | 每个节点一个,负责本地任务调度、资源管理 | 类似 K8s 里的 kubelet |
| Object Store | 基于共享内存(Plasma),存中间结果 | 类似 Redis,但跑在内存里 |
| Worker | 真正执行你 Python 函数的进程 | 类似线程池里的 worker |
2.3 一次任务调用,背后发生了什么?
假设你写了这样一行代码:
1result = my_func.remote(big_array)
底层流程是这样的:
sequenceDiagram
participant D as Driver
participant LR as 本地 Raylet
participant OS as Object Store
participant RR as 远程 Raylet
participant W as Worker
D->>OS: 1. 把 big_array 放进共享内存
OS-->>D: 返回 ObjectRef (相当于指针)
D->>LR: 2. 提交任务 my_func(ObjectRef)
LR->>LR: 3. 决定调度到哪个节点
LR->>RR: 4. 转发到目标节点的 Raylet
RR->>OS: 5. 拉取 big_array 到本地
RR->>W: 6. 启动 Worker 执行函数
W->>OS: 7. 把结果写回 Object Store
W-->>D: 返回 result ObjectRef
关键点:
- 零拷贝:
big_array通过 Plasma 共享内存传递,同节点上的 Worker 可以直接读,不用复制 - 数据本地化:调度器优先把任务派到数据所在的节点
- 延迟执行:
.remote()立即返回,函数还没真正跑,你拿到的是一个"期货"(ObjectRef)
2.4 三个核心原语
Ray 的所有 API,本质上都是这三个东西的组合:
graph LR
subgraph "Ray 三大原语"
Task[Task 任务
无状态函数]
Actor[Actor 有状态对象
类的实例]
Object[Object 对象
不可变数据]
end
Task -->|读| Object
Task -->|写| Object
Actor -->|读| Object
Actor -->|写| Object
Task -.->|可以创建| Actor
style Task fill:#bbf,stroke:#00c
style Actor fill:#fbb,stroke:#c00
style Object fill:#bfb,stroke:#0a0
- Task:无副作用的纯函数,可以被随意分发、重试、并行
- Actor:有状态的对象,相当于一个常驻进程,可以保存模型、连接、缓存
- Object:所有函数的输入输出,存在 Object Store 里,跨进程共享
记住这三个,下面所有 Ray 代码你都看得懂。
2.5 一个直观例子:树形归约(Tree Reduction)
光说"并行"很抽象。下面这个加法例子是 Ray 官方课件里反复用的,看完你就明白为什么 .remote() 必须返回 ObjectRef 而不是值。
任务:把 8 个数两两相加,最后归约到一个结果。
串行写法:
1@ray.remote
2def add(a, b): return a + b
3
4# 7 步依赖链,每步等前一步
5id1 = add.remote(1, 2) # 1 + 2 = 3
6id2 = add.remote(id1, 3) # 3 + 3 = 6
7id3 = add.remote(id2, 4) # 6 + 4 = 10
8id4 = add.remote(id3, 5) # 10 + 5 = 15
9id5 = add.remote(id4, 6) # 15 + 6 = 21
10id6 = add.remote(id5, 7) # 21 + 7 = 28
11id7 = add.remote(id6, 8) # 28 + 8 = 36
12ray.get(id7) # 36
7 个任务必须排成一条直线,深度 O(n)。即便给你 8 个 CPU,也只有 1 个能干活。
树形写法:
1# 第 1 层:4 个 add 任务并发跑
2id1 = add.remote(1, 2)
3id2 = add.remote(3, 4)
4id3 = add.remote(5, 6)
5id4 = add.remote(7, 8)
6
7# 第 2 层:2 个 add 任务并发,等第 1 层
8id5 = add.remote(id1, id2)
9id6 = add.remote(id3, id4)
10
11# 第 3 层:1 个 add 任务,等第 2 层
12id7 = add.remote(id5, id6)
13
14ray.get(id7) # 36
任务总数还是 7 个,但深度只有 log₂(8) = 3。8 核机器上理论可以 3 步跑完,而不是 7 步。
graph BT
A1[1] --> S1[add]
A2[2] --> S1
A3[3] --> S2[add]
A4[4] --> S2
A5[5] --> S3[add]
A6[6] --> S3
A7[7] --> S4[add]
A8[8] --> S4
S1 --> M1[add]
S2 --> M1
S3 --> M2[add]
S4 --> M2
M1 --> F[add → 36]
M2 --> F
style F fill:#dfe,stroke:#0a0
这里有个非常重要的细节:id1/id2/… 都是 ObjectRef,不是数字。当 add.remote(id1, id2) 时,Ray 看到参数里有 ObjectRef,就自动建立依赖:这个任务必须等 id1 和 id2 算完才能跑。
这就是为什么
.remote()必须返回ObjectRef而不是同步阻塞拿真值——只有这样,你才能在还没拿到结果的时候就把后续的 task 链表全部提交出去,让 Ray 调度器看到完整 DAG,自动安排并行。
这也是 Task 区别于普通线程池的关键:线程池只能"分发 → 等结果 → 再分发",Ray 让你一次性把整张 DAG 描述完,调度器自己看哪些 task 可以并行、哪些必须串行。
三、动手:搭一个最小的 Ray 集群
3.1 安装
1pip install "ray[default]>=2.40,<3"
2pip install lightgbm pandas pyarrow scikit-learn
本文实测用的是 Ray 2.49.2 + Python 3.13.7 + LightGBM 4.6.0。Ray 在 2.x 系列里 API 有过细节变动(比如 tune.report 的签名),跨 minor 版本时请对照官方升级文档。
3.2 单机启动
最简单的玩法,直接在脚本里 ray.init() 就行:
1import ray
2
3ray.init()
4
5@ray.remote
6def hello(name):
7 return f"hello, {name}"
8
9futures = [hello.remote(f"worker-{i}") for i in range(8)]
10print(ray.get(futures))
ray.init() 会在本机起一个完整的 Ray 集群(GCS + Raylet + Object Store),只用本机的 CPU。
3.3 多机启动
实际生产中你会有一台 Head 和多台 Worker:
1# Head 节点
2ray start --head --port=6379 --dashboard-host=0.0.0.0
3
4# Worker 节点(在另一台机器上跑)
5ray start --address='<head-ip>:6379'
然后在 Driver 程序里这样连:
1ray.init(address='auto') # 自动连接到本地已经启动的集群
打开 http://<head-ip>:8265 就能看到 Ray 自带的仪表盘,能实时看到任务、Actor、内存、CPU 等。
3.4 一个核心坑:不要在 remote 函数里再 ray.init()
1# 错误示范
2@ray.remote
3def bad_func():
4 ray.init() # ❌ 会报错或产生奇怪行为
5 return 1
6
7# 正确:Driver 里 init 一次就够
8ray.init()
9
10@ray.remote
11def good_func():
12 # 直接用就行,Worker 已经连接到集群了
13 return 1
四、Ray 在金融建模中的典型应用场景
在跳进 LightGBM 实战前,先了解一下 Ray 在量化场景下到底能加速什么。
graph TD
subgraph "金融建模流水线"
A[1. 数据加载
Ray Data] --> B[2. 特征工程
Ray Tasks]
B --> C[3. 超参搜索
Ray Tune]
C --> D[4. 模型训练
Ray Train]
D --> E[5. 回测/推理
Ray Actor Pool]
end
style A fill:#bfd,stroke:#0a0
style B fill:#bfd,stroke:#0a0
style C fill:#fbd,stroke:#a00
style D fill:#fbd,stroke:#a00
style E fill:#bdf,stroke:#00a
| 阶段 | Ray 工具 | 加速方式 |
|---|---|---|
| 数据加载 | ray.data |
并行读 Parquet/CSV,自动分片 |
| 特征工程 | @ray.remote Task |
按股票/按日期切分并行算因子 |
| 超参搜索 | ray.tune |
并行跑成百上千组超参组合 |
| 分布式训练 | ray.train |
LightGBM/XGBoost/PyTorch 多机训练 |
| 滚动回测 | Ray Actor Pool | 每个回测窗口一个 Actor |
下面我们用一个完整例子串起来。但在那之前,先把 Ray 里跟金融建模最相关的几个模块单独讲清楚 —— 尤其是 Tune,文章后面会反复用到。
4.1 Ray Tasks:函数级并行的底盘
@ray.remote 把任意 Python 函数变成可分布式调度的"任务"。三个关键属性:
- 延迟执行:
f.remote(...)立即返回ObjectRef,函数还没真跑 - 资源声明:
@ray.remote(num_cpus=2, memory=4*1024**3, num_gpus=0.5)告诉 Ray 这个任务要多少资源 - 自动 deref:把
ObjectRef作为参数传给另一个@ray.remote函数时,Ray 会自动在 worker 内 deref,所以函数体内拿到的是真实对象(不是 ObjectRef,不要再ray.get,否则会报Invalid type of object refs)
适用场景:embarrassingly parallel,比如本文第五章按窗口并行、第六章按文件并行算特征。
4.2 Ray Actors:有状态的"长寿命对象"
@ray.remote 加在类上,类的每个实例就成了一个常驻的 Worker 进程,调用方法时还是 .remote():
1@ray.remote(num_cpus=1)
2class FeatureCache:
3 def __init__(self):
4 self.cache = {}
5 def get(self, key): return self.cache.get(key)
6 def put(self, key, val): self.cache[key] = val
7
8cache = FeatureCache.remote()
9ray.get(cache.put.remote("k", 1))
什么时候用 Actor 不用 Task?
- 想保留状态(缓存、连接池、加载好的大模型)
- 多个 Task 需要轮询同一个外部资源(GPU、DB 连接)
- 在线推理服务(虽然 Ray Serve 自己更专业)
经典 Actor 案例:Parameter Server
Ray 官方课件用得最多的一个 Actor 例子就是 Parameter Server。它把分布式训练里"全局共享一份参数 + 多个 worker 异步更新"这个模式用十几行代码搭出来:
1import numpy as np
2import ray
3
4@ray.remote
5class ParameterServer:
6 """全局共享的参数表,由 Ray Actor 托管。"""
7 def __init__(self, dim=10):
8 self.params = np.zeros(dim)
9 def get_params(self):
10 return self.params
11 def update_params(self, grad):
12 self.params -= grad
13 return self.params
14
15@ray.remote(num_gpus=1)
16def worker(ps):
17 """每个 worker 进程:拉参数 → 算梯度 → 推回 PS。"""
18 while True:
19 params = ray.get(ps.get_params.remote())
20 grad = compute_gradient(params) # 真实场景里用 TF/PyTorch
21 ps.update_params.remote(grad)
22
23# 启动
24ps = ParameterServer.remote()
25workers = [worker.remote(ps) for _ in range(8)] # 8 个 GPU worker
注意三个关键设计:
ps是一个 Actor handle,可以当普通对象传给任何 worker。Ray 内部维护它的位置,所有 worker 通过 RPC 调用同一个进程ps.get_params.remote()返回 ObjectRef,配合ray.get拿当前参数;update_params.remote(grad)是 fire-and-forget,不阻塞- 8 个 worker 异步 + 同一个 PS:天然的 async SGD。要做 sync SGD 就给 PS 加个 step 计数器和屏障
这套模式直接搬到金融场景:把 ParameterServer 换成"特征缓存 actor"或"在线推理模型 actor",配合多个 worker task 抽特征/打分,就是本文 6.10 节"特征池 + 全自动 Meta 模型搜索"那张架构图的雏形。
4.3 Ray Tune:本文主角,重点展开
Tune 是 Ray 里专门做超参搜索的子库,本文第五章第六章都依赖它。它把"在一组超参上跑实验、记录指标、按调度器决定继续/早停"这个循环封装成一个 declarative API。
从普通 Python 训练函数到全功能 Tune:七步阶梯
下面这个阶梯从一个最朴素的训练函数开始,每一步只多写一行就多解锁一项 Tune 能力。你可以照着这个梯子去理解 Tune API 是怎么"长"出来的,用到哪步停在哪步。
Step 1. 一个再普通不过的训练函数。和单机训练一模一样,不依赖 Ray:
1def train_model(config):
2 model = ConvNet(config)
3 for i in range(steps):
4 loss, acc = model.train()
Step 2. 在训练循环里上报一个指标,让外部能"看见"训练状态:
1from ray import tune
2
3def train_model(config):
4 model = ConvNet(config)
5 for i in range(steps):
6 loss, acc = model.train()
7 tune.report({"mean_loss": loss}) # ⬅️ 唯一改动
Step 3. 直接当普通 Python 跑(Tune 还没接管,纯调试用):
1train_model({"learning_rate": 0.1})
Step 4. 让 Tune 接管:一行 tune.run,单 trial 跑一次:
1tune.run(train_model, config={"learning_rate": 0.1})
Step 5. 加 num_samples 让多 trial 并行(Tune 自动按集群核数排队):
1tune.run(train_model,
2 config={"learning_rate": 0.1},
3 num_samples=100)
Step 6. 加 upload_dir 自动把日志和 checkpoint 同步到 S3(或本地路径),TensorBoard 和 JSON 双格式:
1tune.run(train_model,
2 config={"learning_rate": 0.1},
3 num_samples=100,
4 upload_dir="s3://my_bucket/run-2026")
Step 7. 把 config 里的固定值替换成搜索空间,加调度器和搜索算法,正式上 Tune:
1from ray.tune.schedulers import PopulationBasedTraining
2from ray.tune.search.optuna import OptunaSearch
3
4tune.run(
5 train_model,
6 config={"learning_rate": tune.uniform(0.001, 0.1)},
7 num_samples=100,
8 upload_dir="s3://my_bucket/run-2026",
9 scheduler=PopulationBasedTraining(),
10 search_alg=OptunaSearch(),
11)
注意:新版 Ray(2.x+)推荐用 tune.Tuner(...).fit() 风格的 API,本文其它示例都用了它。tune.run() 是 1.x 时代的写法,逻辑等价,七步阶梯里我留旧 API 是为了一步一步看清概念,生产代码请用 Tuner。
一个最小可跑的 Tuner 写法
回到我们实际用的 API:
1from ray import tune
2from ray.tune.schedulers import ASHAScheduler
3
4def trainable(config):
5 # 训练你的模型...
6 tune.report({"logloss": ...}) # 上报指标
7
8tuner = tune.Tuner(
9 trainable,
10 tune_config=tune.TuneConfig(
11 metric="logloss", mode="min",
12 scheduler=ASHAScheduler(max_t=100, grace_period=10),
13 num_samples=64,
14 ),
15 param_space={
16 "lr": tune.loguniform(1e-3, 1e-1),
17 "leaves": tune.choice([31, 63, 127]),
18 },
19)
20results = tuner.fit()
21print(results.get_best_result().config)
Tune 有四个值得知道的旋钮:
(a) 搜索空间:tune.* 采样函数
| API | 用途 |
|---|---|
tune.choice([...]) |
离散选项,等概率 |
tune.grid_search([...]) |
全部枚举(不抽样) |
tune.uniform(a, b) |
连续均匀 |
tune.loguniform(a, b) |
对数均匀(学习率、正则系数首选) |
tune.randint(a, b) |
整数均匀 |
tune.sample_from(lambda spec: ...) |
条件采样(依赖其它参数) |
(b) 搜索算法(怎么从搜索空间里挑下一组)
| Search Algorithm | 何时用 |
|---|---|
BasicVariantGenerator(默认) |
完全随机 / 网格 |
HyperOptSearch |
基于 Tree-Parzen Estimator (TPE) 的贝叶斯优化 |
OptunaSearch |
接入 Optuna,复用其采样器 |
BayesOptSearch |
标准贝叶斯优化(连续空间) |
BOHB |
贝叶斯 + HyperBand 联合 |
简单场景随机就够;超参 > 6 个、单次训练 > 5 min 时,TPE / Optuna 能省 30-50% 试验数。
(c) 调度器(决定 trial 早停还是继续)
| Scheduler | 思想 | 何时用 |
|---|---|---|
FIFOScheduler(默认) |
不早停,按顺序跑完所有 trial | 单次训练很快、或不能中间报告指标 |
ASHAScheduler |
Async Successive Halving,差的早砍 | 通用首选,前提是能定期 tune.report |
HyperBandScheduler |
同步版 SHA | 资源严格固定时 |
PopulationBasedTraining (PBT) |
跑一组 trial,差的复制好的并扰动超参 | 长训练(RL、深度模型) |
BOHB |
Bayesian + HyperBand | 想结合贝叶斯采样 + 早停 |
第五章我用了 ASHA,第六章每个 trial 都跑完了 3 折所以用默认 FIFO。
(d) 资源 & 并发:避免死锁的关键
1tune.with_resources(trainable, resources={"cpu": 2})
2tune.TuneConfig(max_concurrent_trials=5, ...)
- 每个 trial 申请的 CPU 必须 ≤ 集群总 CPU
- trial 内部如果再起
@ray.remote子任务,子任务默认会被绑定到 trial 的 placement group bundle 上,bundle 装不下就会死锁或报错。第六章我踩过这个坑,最干净的解法是不在 trainable 里嵌套 remote,3 折直接串行跑
(e) 持久化与续跑
results.errors 能查看哪些 trial 挂了,Tuner.restore(...) 能从 checkpoint 继续跑——长时间训练(>1h)务必开 checkpoint:
1from ray.train import CheckpointConfig
2tune.RunConfig(checkpoint_config=CheckpointConfig(num_to_keep=1))
(f) TensorBoard 可视化全家桶
Tune 默认会把每个 trial 的指标、超参、checkpoint 都写到 ~/ray_results/<experiment>/ 下。只要指标命名规范,TensorBoard 的 HParams plugin 就能直接拉起来,把"超参 → metric"的相关性矩阵、并行坐标图、过滤器一起给你。
前置一步:默认 Tune 只写 JSON/CSV,要让 TensorBoard 识别,需要显式加 TBXLoggerCallback:
1from ray import tune, train
2from ray.tune.logger import TBXLoggerCallback
3
4tuner = tune.Tuner(
5 trainable,
6 tune_config=tune.TuneConfig(metric="auc", mode="max", num_samples=12),
7 run_config=train.RunConfig(
8 name="my_experiment",
9 callbacks=[TBXLoggerCallback()], # ⬅️ 关键
10 storage_path="~/ray_results",
11 ),
12 param_space={...},
13)
14tuner.fit()
第一次跑会提示装两个依赖:
1pip install tensorboard tensorboardX
然后启动 TensorBoard:
1tensorboard --logdir=~/ray_results --port=6006
2# 浏览器打开 → 切到 HPARAMS 标签
下面所有截图都来自我本机跑的 12 trial Tune 实验:搜索 LightGBM 的 learning_rate / num_leaves / n_estimators 三个超参,metric 看 auc 和 logloss。
(f.1) Scalars 视图:看每个 trial 训练过程的曲线
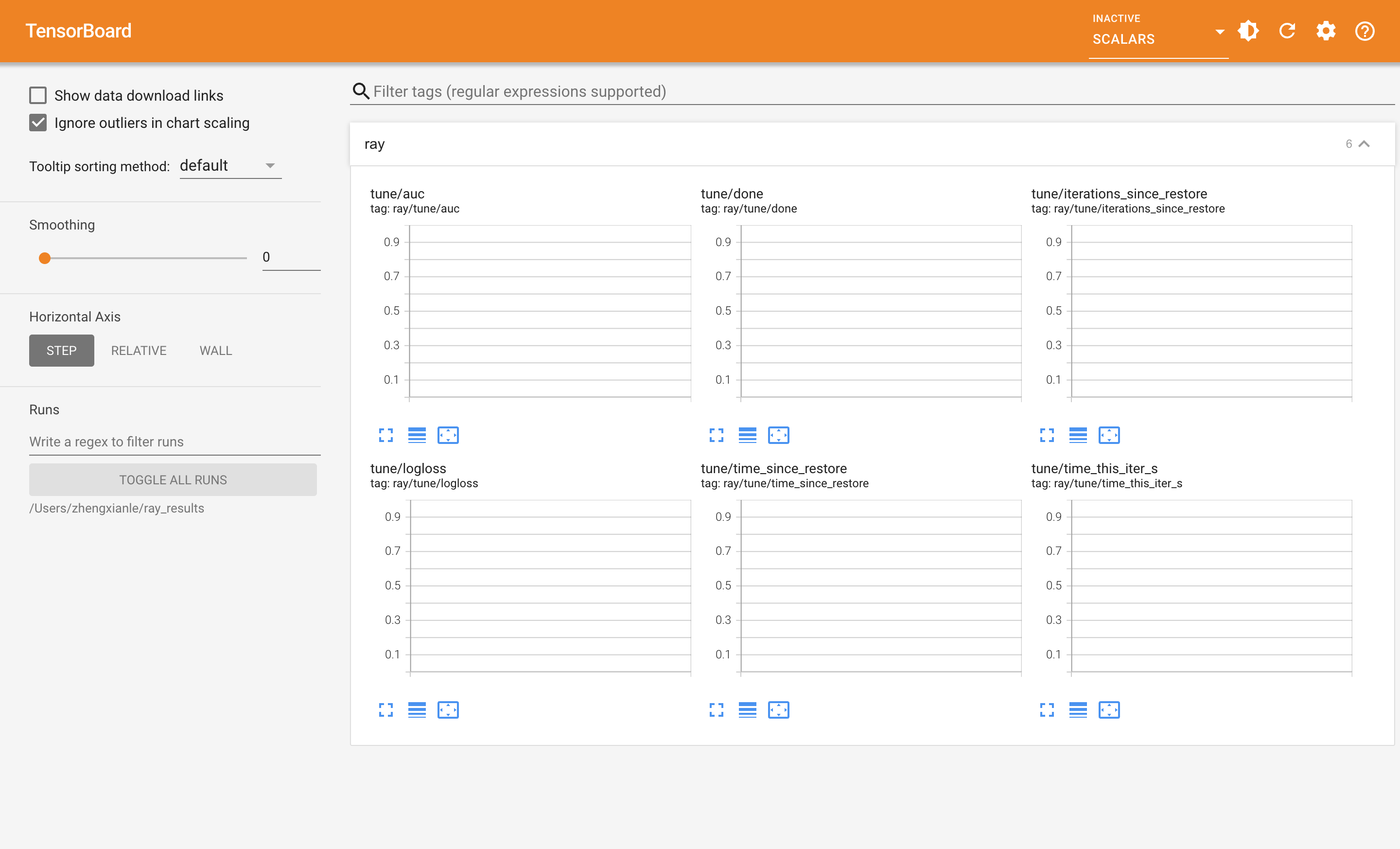
这张图我以前老忽略,后来才发现是最常用的。左侧面板是"哪些指标可选"——tune/auc / tune/done / tune/iterations_since_restore / tune/logloss / tune/time_since_restore / tune/time_this_iter_s 都是 Tune 自动写进去的。右侧每个小窗口是一个指标在 12 个 trial 上的曲线。
怎么读这张图:
- 每条彩色线是一个 trial(颜色和 HParams 表格里的 trial 颜色一一对应)
- X 轴是 step(这里因为我们的 trainable 只调一次
tune.report,所以每条线就一个点) - 在我们这个 LightGBM 例子里,因为每个 trial 只跑一次
fit,所以 Scalars 不是关键;但如果你的 trainable 是迭代式的(比如每个 epoch 都tune.report一次),这里就会变成"训练曲线大全",能看出哪些 trial 收敛快、哪些震荡、哪些卡在某个 loss 上不动了
金融建模里的实战用法:把 LightGBM 的 early_stopping_rounds 改成 callback,每 10 轮 boost 报告一次 valid_logloss,Scalars 视图就能直接看到"learning_rate 高的 trial 前 50 轮掉得快但后期不稳"这类形态。
(f.2) HParams 表格视图:12 个 trial 一字排开做对比
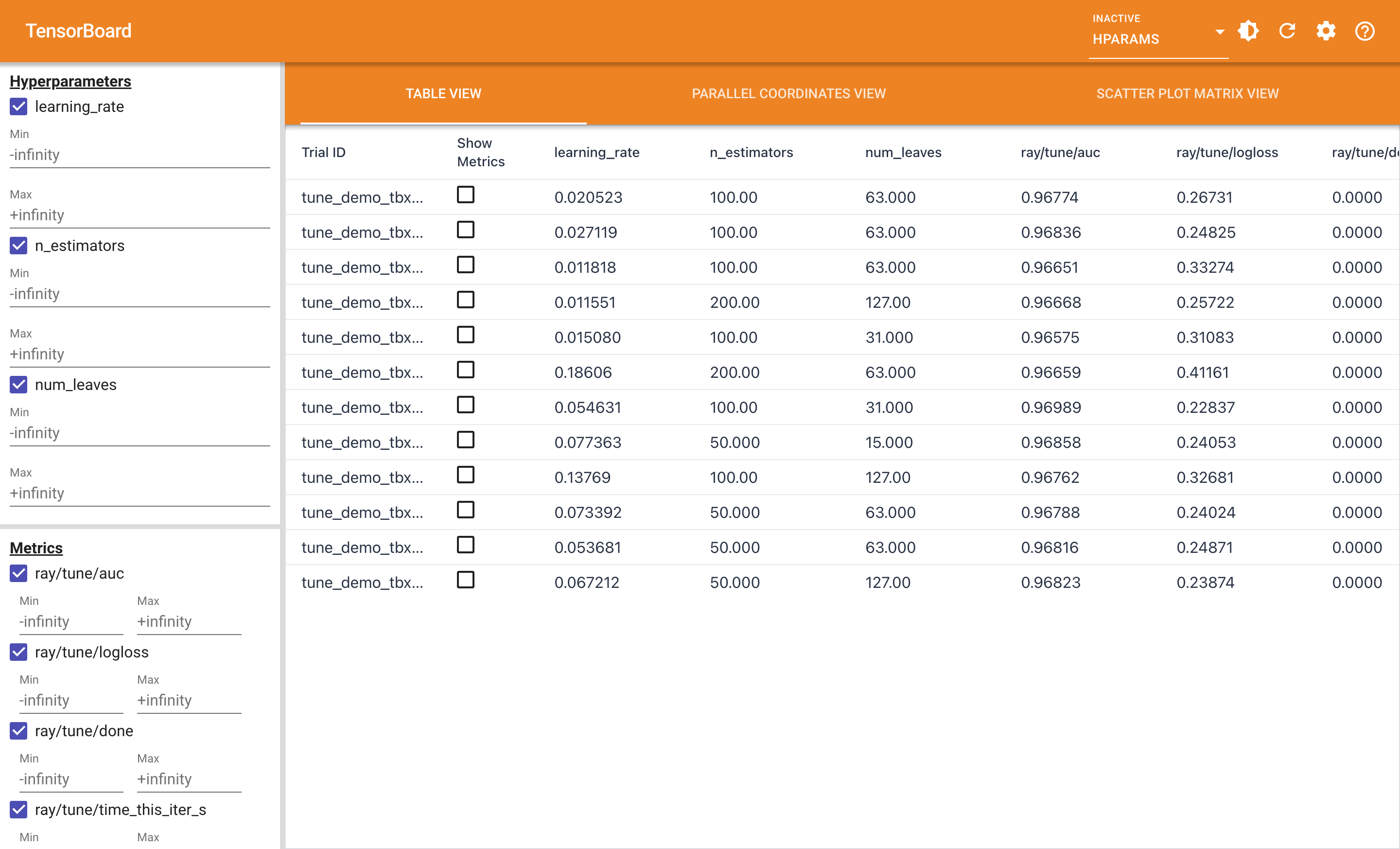
这是 HParams 标签页的默认视图。左边筛选区可以按超参范围 / 状态过滤,右边主表 12 行 × 9 列:
| 列 | 含义 | 我这次的数据范围 |
|---|---|---|
| Trial ID | 自动生成的短哈希 | 7e869_00000 ~ 7e869_00011 |
| Show Metrics | 勾选后会在右下角画该 trial 的指标小图 | — |
learning_rate |
我搜的超参 | 0.0118 ~ 0.1861 |
n_estimators |
我搜的超参 | 50 / 100 / 200 |
num_leaves |
我搜的超参 | 15 / 31 / 63 / 127 |
ray/tune/auc |
metric,越大越好 | 0.9658 ~ 0.9699 |
ray/tune/logloss |
metric,越小越好 | 0.2284 ~ 0.4116 |
ray/tune/done |
trial 是否完成(0/1) | 全部 1,因为已结束 |
ray/tune/time_this_iter_s |
单 iter 耗时 | 0.22s ~ 9.44s |
读这张图最有信息量的几个点:
- 最佳 trial #6 拿到
auc=0.96989,配置是learning_rate=0.05463, n_estimators=100, num_leaves=31。比第二名 #1(auc=0.96836)只高 0.0015,但 #1 跑了 2.25 秒,#6 跑了 1.82 秒——精度和速度都赢 - trial #5(
learning_rate=0.1861, num_leaves=63, n_estimators=200)耗时 9.4s 最长,但 logloss 反而是 0.4116 最差——典型的"学习率太高 + 树太多 → 过拟合到训练集" - trial #7(
learning_rate=0.0774, num_leaves=15, n_estimators=50)只用了 0.22 秒就拿到 0.9686 的 auc,是 ROI 最高的配置——当你计算预算紧张时,这种配置值得优先尝试
可以点击右上角的 CSV/JSON/LaTeX 把这张表导出来直接放进汇报里。
(f.3) HParams 平行坐标视图:一眼看出哪段超参区间最稳
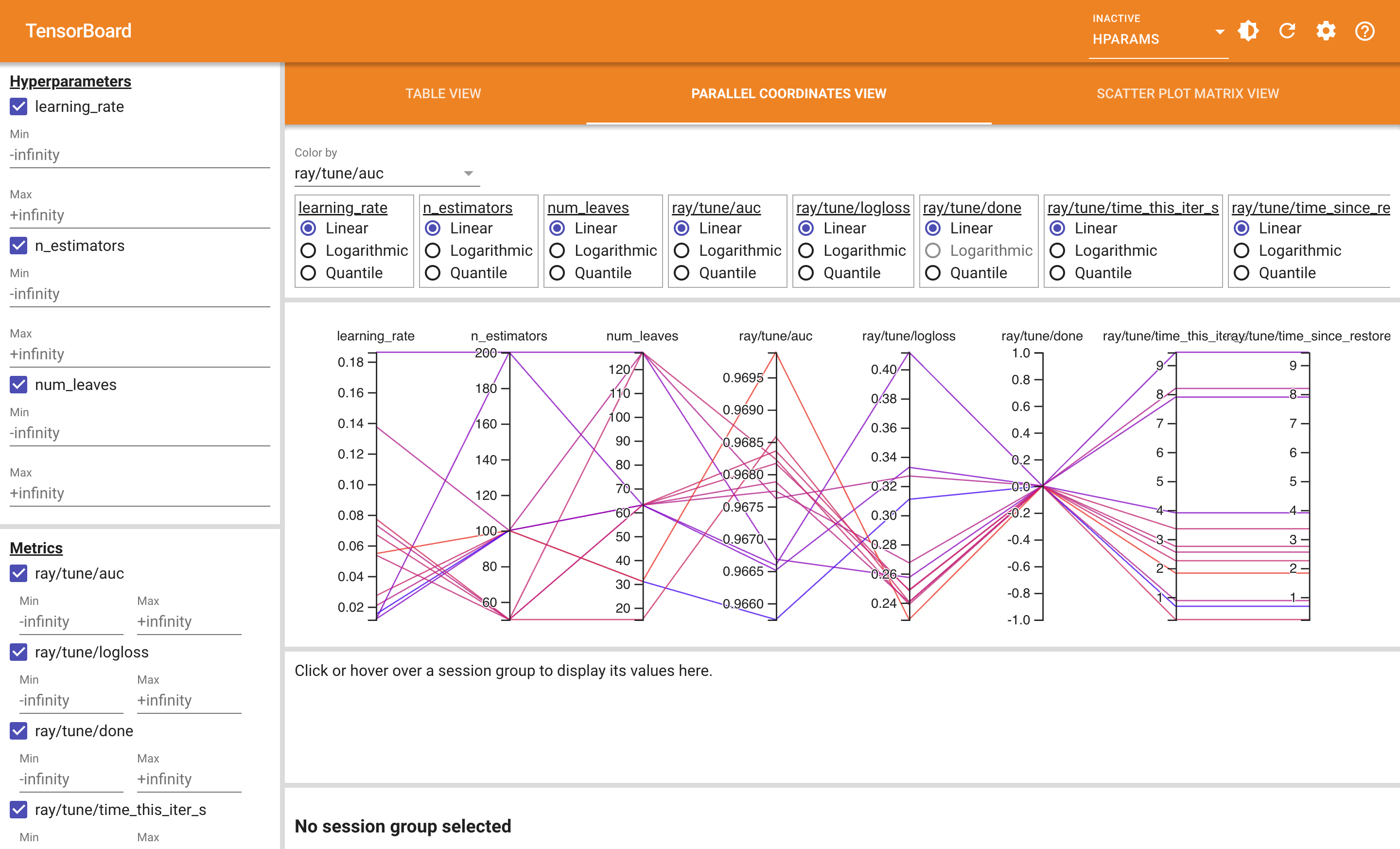
这是 HParams 里最值得花时间看的一张图。每条折线 = 一个 trial,从左到右依次穿过每个超参轴和 metric 轴。颜色按 auc 编码(图例可改),深色=高 AUC,浅色=低 AUC。
怎么读这张图:
- 沿
learning_rate轴看:深色线集中在 0.04-0.08 区间(trial #6 / #7 / #11 / #10),最浅的几条线落在 0.13+ 区间(trial #8 / #5)。结论:学习率别开太大 - 沿
num_leaves轴看:深色线在 31 和 63 之间,127 区间偏浅。结论:树太复杂没好处 - 沿
n_estimators轴看:50 / 100 都有深色线,200 反而偏浅。结论:不用堆太多树,配合好的学习率,少量树就够 - 看
ray/tune/auc轴右侧的小三角:所有线都挤在 0.966-0.970 之间,说明这个数据集所有超参组合性能差异不大(典型的"模型对超参不敏感"信号)—— 如果你看到的是一个轴上线散开十倍以上,那说明这个超参才是关键,值得继续放大搜索范围
最有用的交互:在任意轴上拖一个 brush 框(用鼠标在轴上画一段区间),符合范围的线会高亮、其它变灰,比看 CSV 强 10 倍。
(f.4) HParams 散点矩阵视图:看任意两两超参/指标的相关性
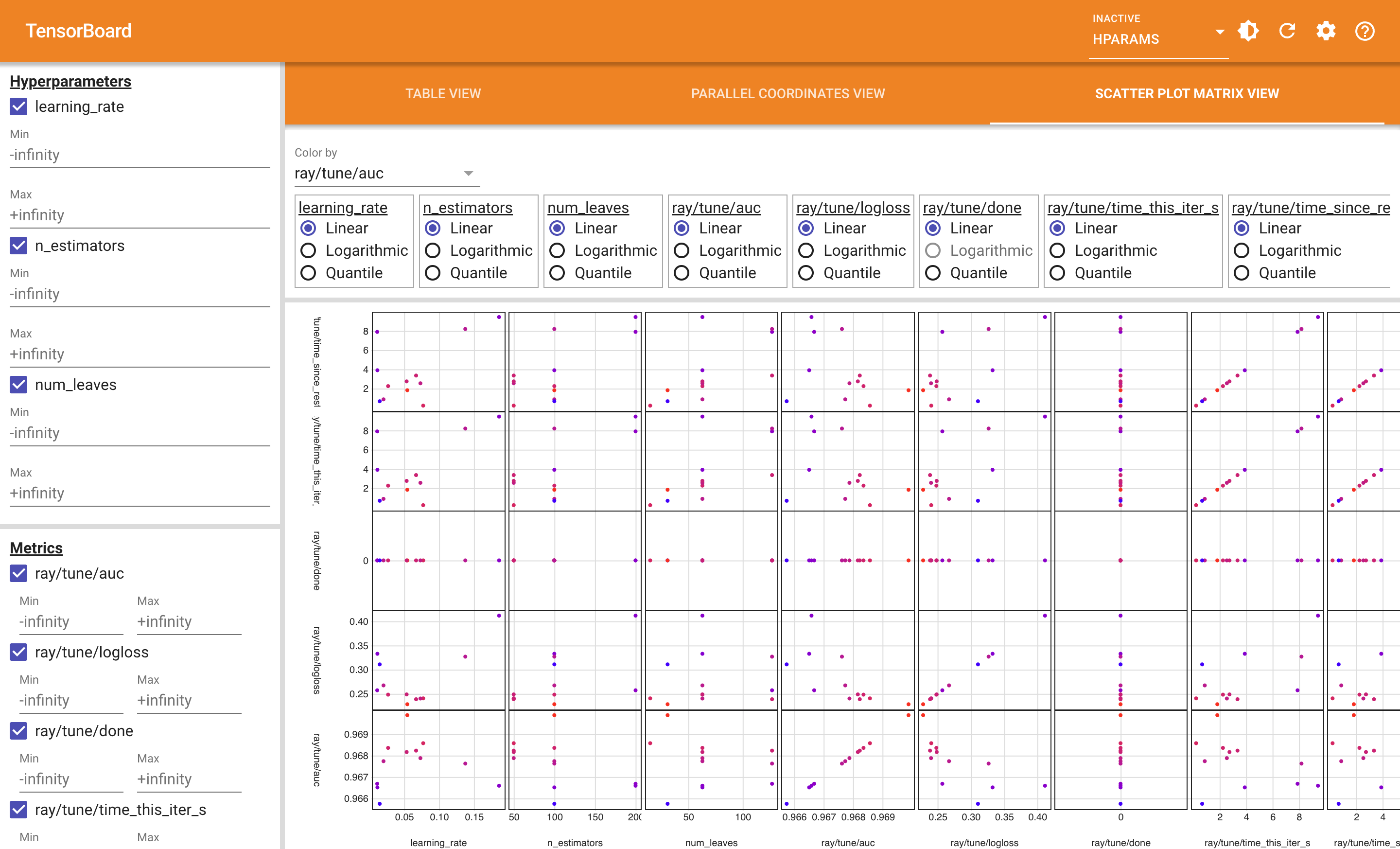
散点矩阵把所有超参 × 所有指标的"两两关系"画成一个 N×N 的小图阵。每个小格子里都是 12 个点(12 个 trial),坐标按对应的两个变量。
怎么读这张图:
- 看
learning_rate × ray/tune/auc那一格(最左列、第 4 行):呈倒 U 型——learning_rate 在 0.04-0.08 区间 auc 最高,过低(0.01)或过高(0.18)都掉 - 看
learning_rate × ray/tune/logloss(第 5 行):单调递增——learning_rate 越高 logloss 越糟。这个和 auc 的倒 U 一致:高学习率虽然 auc 还行,但模型的概率校准(logloss)会被破坏 - 看
n_estimators × ray/tune/time_this_iter_s(第 6 行):完美线性正相关,符合常识(树越多越慢) - 看
num_leaves × auc:几乎没有相关性——这告诉我下次搜索可以把 num_leaves 固定成 31 节省搜索预算
和平行坐标图的区别:散点矩阵看的是两两变量之间的具体形态(线性 / U 型 / 噪声),平行坐标看的是多变量同时筛选。配合用:先用散点矩阵找形态,再用平行坐标 brush 缩窄搜索范围。
(f.5) Time Series 视图:新版指标时间线
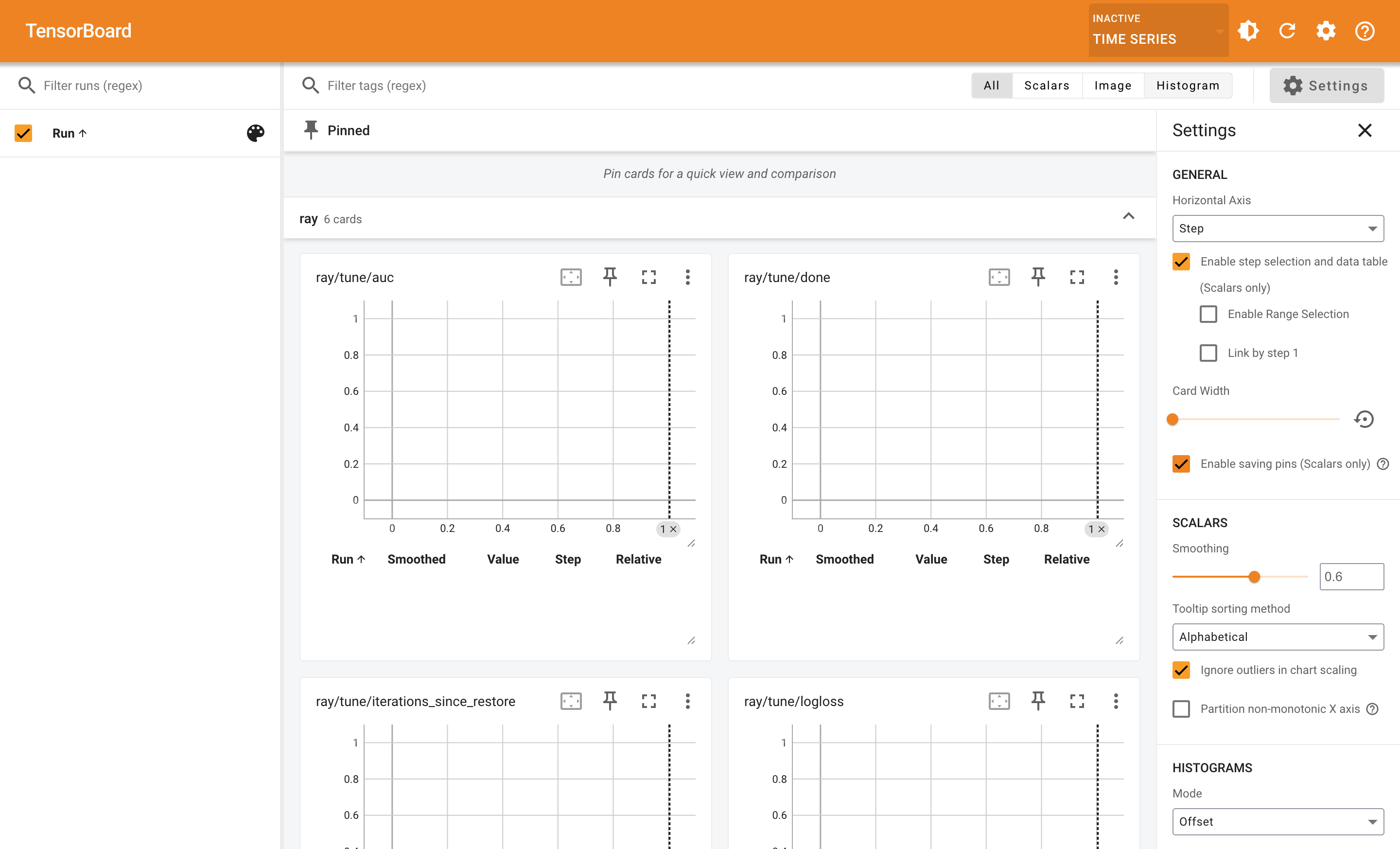
Time Series 是 TensorBoard 较新的视图(取代部分 Scalars 功能),把每个指标做成独立卡片,支持双击放大、按住 Alt+滚轮缩放。比老 Scalars 视图更适合做"看一个 trial 的训练曲线细节"。
我们这次的 trainable 只 tune.report 一次,所以每条线都只有一个 step。但如果你在 trainable 里加循环上报,这里就是查看"哪个 trial 最早收敛、哪个突然崩了"的最佳入口。
HParams 全家桶能做什么
| 视图 | 用来 |
|---|---|
| Scalars / Time Series | 看每个 trial 训练过程的曲线,找收敛快慢、发散 |
| HParams Table | 严格对比所有 trial 的指标,导出汇报 |
| Parallel Coordinates | 找超参的"安全区间",brush 后立刻缩窄搜索 |
| Scatter Plot Matrix | 看两两变量的形态,找冗余 / 不敏感的超参 |
HParams 视图主要能干两件事:
- 找出哪些超参对 metric 真正敏感:并行坐标图上拖范围,立刻看到哪些超参组合稳定出高分
- 跨 sweep 复用历史搜索状态(warm starting):把同一个
storage_path复用,下次搜索时可以在 TensorBoard 里同时看到历史 + 新的 trial
如果你用 storage_path="s3://..." 把 logdir 同步到对象存储,团队所有人都能用同一份 TensorBoard 看到所有人的实验结果——这是把"个人调参"变成"团队共享 leaderboard"的关键。
(g) Population-Based Training (PBT):长训练的"进化算法"
ASHA 是"差的早砍",PBT 走的是另一条路:让一群 trial 同时跑,定期把表现差的 trial 用好的 trial 的权重 + 微扰超参替换掉。本质是一种进化算法,对长训练(RL / LLM finetuning)特别有效,因为它把"搜超参"和"训练"耦合在同一个长时间过程里。
1from ray.tune.schedulers import PopulationBasedTraining
2
3pbt = PopulationBasedTraining(
4 time_attr="training_iteration",
5 perturbation_interval=5, # 每 5 个 iter 检查一次该不该替换
6 hyperparam_mutations={
7 "lr": tune.loguniform(1e-5, 1e-2),
8 "weight_decay": tune.uniform(0, 0.1),
9 },
10 quantile_fraction=0.25, # 后 25% 被前 25% 覆盖
11 resample_probability=0.25, # 25% 概率重新采样,75% 概率 *1.2 / *0.8 扰动
12)
13
14tuner = tune.Tuner(
15 trainable,
16 tune_config=tune.TuneConfig(
17 metric="reward", mode="max",
18 scheduler=pbt, num_samples=8,
19 ),
20 param_space={
21 "lr": tune.loguniform(1e-5, 1e-2),
22 "weight_decay": tune.uniform(0, 0.1),
23 },
24)
PBT 适合什么 / 不适合什么:
- ✅ 训练 > 1 小时,能定期 checkpoint 又能从 checkpoint 加载(PBT 要复制权重)
- ✅ 超参对训练中后期影响很大(学习率 schedule、warmup、KL 系数等)
- ❌ 单次训练 < 10 分钟:PBT 的 checkpoint 复制开销盖过收益
- ❌ trainable 是无状态的 fit-once 模式(LightGBM 单次
.fit()):PBT 起不来
量化里典型场景:Foundation Model 持续预训练时用 PBT 自动调 lr 和 dropout。
(h) BOHB:贝叶斯优化 + HyperBand 的合体
BOHB 把"贝叶斯采样"和"HyperBand 早停"合到一起,号称 state-of-the-art。当你的搜索空间维度高(10+)、单次训练贵、要榨干每一份算力时选它:
1from ray.tune.schedulers import HyperBandForBOHB
2from ray.tune.search.bohb import TuneBOHB
3
4bohb_search = TuneBOHB(metric="auc", mode="max")
5bohb_sched = HyperBandForBOHB(time_attr="training_iteration",
6 max_t=100, reduction_factor=3)
7
8tuner = tune.Tuner(
9 trainable,
10 tune_config=tune.TuneConfig(
11 scheduler=bohb_sched,
12 search_alg=bohb_search,
13 num_samples=128,
14 ),
15 param_space={...},
16)
怎么从 ASHA / PBT / BOHB 三个里选:
| 你的情况 | 选 |
|---|---|
| 单 trial < 1 min、想快试错 | ASHA |
| 单 trial > 1 hour,搜参数也搜训练动态(lr schedule 等) | PBT |
| 单 trial 几分钟到一小时,搜索空间大(10+ 维),愿意装 hpbandster | BOHB |
| 完全不了解、不想做选择 | ASHA(最稳) |
(i) 多目标优化:Pareto Front 而不是单点最优
量化里经常要同时优化多个指标——既要 AUC 高,又要换手率低(控制交易成本);既要 Sharpe 高,又要回撤小。这是典型的多目标问题,单点最优答案不一定存在,正确做法是找 Pareto 前沿:
1from ray.tune.search.optuna import OptunaSearch
2
3tuner = tune.Tuner(
4 trainable,
5 tune_config=tune.TuneConfig(
6 # 多目标:metric 改成 list,mode 也对应 list
7 metric=["auc", "turnover"],
8 mode=["max", "min"],
9 search_alg=OptunaSearch(metric=["auc", "turnover"], mode=["max", "min"]),
10 num_samples=100,
11 ),
12 param_space={...},
13)
14results = tuner.fit()
15
16# 不再有 get_best_result,要遍历找 Pareto 前沿
17import pandas as pd
18df = results.get_dataframe()
19# 简单 Pareto:对每行检查是否被其它行"全方位碾压"
20def is_pareto(row, df):
21 dominated = (df["auc"] >= row["auc"]) & (df["turnover"] <= row["turnover"]) \
22 & ((df["auc"] > row["auc"]) | (df["turnover"] < row["turnover"]))
23 return not dominated.any()
24pareto = df[df.apply(lambda r: is_pareto(r, df), axis=1)]
不同 trial 在 Pareto 前沿上代表不同的 trade-off,让业务方挑哪个点最符合策略偏好——比单点最优更尊重真实决策过程。
(j) Tuner.restore:trial 挂了之后接着跑
长时间训练最怕"跑 3 天最后挂了"。Ray Tune 的 checkpoint + restore 机制让你能从断点续跑:
1# 第一次跑:定义 RunConfig 并自动 checkpoint
2tuner = tune.Tuner(
3 trainable,
4 tune_config=tune.TuneConfig(num_samples=100),
5 run_config=train.RunConfig(
6 name="long_search",
7 storage_path="~/ray_results",
8 checkpoint_config=train.CheckpointConfig(
9 checkpoint_at_end=True,
10 checkpoint_frequency=10, # 每 10 个 iter 存一次
11 num_to_keep=3,
12 ),
13 failure_config=train.FailureConfig(max_failures=2), # 单 trial 重试 2 次
14 ),
15 param_space={...},
16)
17tuner.fit()
18
19# 集群崩了 → 重启后从同一个 storage_path 恢复
20tuner = tune.Tuner.restore(
21 "~/ray_results/long_search",
22 trainable=trainable,
23 resume_errored=True, # 失败的 trial 重跑
24 resume_unfinished=True, # 没跑完的接着跑
25)
26tuner.fit()
要点:
storage_path必须放在所有节点都能访问的位置(NFS / S3 / GCS)。本地盘的 checkpoint 在节点挂掉时就丢了max_failures:单个 trial 最多重试几次。超过就标记为 ERRORcheckpoint_frequency:太频繁会拖慢训练;建议设到"挂掉时最多损失 5-10 分钟"的频率Tuner.restore严格要求 同一个 trainable 函数 + 同一个 param_space。改了任何一行都得起新实验
生产里 Ray Train 配合 K8s 时,整个集群被驱逐重建是常态,Tuner.restore 是必备的。
4.4 Ray Data:数据并行的"流式 DataFrame"
ray.data.read_parquet("dir/") 自动按文件分片到多个节点,支持惰性 .map_batches() / .groupby() / .write_parquet()。本文没深入用它,但当数据 > 内存(比如要处理几十 TB 的 tick 数据),它比手写 @ray.remote 文件并行更合适。
量化里最常用的场景:批量推理 / 批量打分
训练完一个模型后,要在全市场上跑一遍打分(“今天对所有 5000 只股票打 0-1 概率”),这是个典型的批量推理任务。用 Ray Data 比手写 task 干净得多:
1import ray
2import numpy as np
3import pandas as pd
4import lightgbm as lgb
5
6ray.init()
7
8# 假设模型已经训练好,pickle 存盘
9import pickle
10bundle = pickle.load(open("meta_model.pkl", "rb"))
11model, feature_cols = bundle["model"], bundle["feature_cols"]
12
13# 1. 用 Ray Data 流式读特征(哪怕 100GB 也不爆内存)
14ds = ray.data.read_parquet("s3://my-bucket/features_today/")
15
16# 2. 定义一个批量推理函数,传给 map_batches
17def score_batch(batch: pd.DataFrame) -> pd.DataFrame:
18 X = batch[feature_cols].fillna(0.0).values
19 prob = model.predict_proba(X)[:, 1]
20 return pd.DataFrame({
21 "stock": batch["stock"].values,
22 "date": batch["date"].values,
23 "prob": prob,
24 })
25
26# 3. map_batches 自动并行 + 控制 batch 大小 + 可选 GPU
27scored = ds.map_batches(
28 score_batch,
29 batch_size=10_000,
30 batch_format="pandas",
31 concurrency=8, # 8 个 worker 并行打分
32 # num_gpus=0.5, # 如果模型在 GPU 上,每 worker 占半张卡
33)
34
35# 4. 流式写回,不需要全量物化到内存
36scored.write_parquet("s3://my-bucket/scores_today/")
注意几个 Ray Data 特有的设计点:
- 惰性执行:
read_parquet → map_batches → write_parquet这一连串都不会触发实际计算,直到write_parquet收尾才开始流转。中间任何一步都不需要把全量数据装内存 batch_format="pandas"vs"numpy"vs"pyarrow":选 pandas 写起来最顺手,但每 batch 转一次格式有开销;选 numpy 性能最好但只能纯数值concurrency=8:开 8 个 worker 并发,Ray 自动调度。要做 GPU 推理时改成num_gpus=0.5让每 worker 占半张卡- 数据本地化:Ray Data 自动感知文件位置,scoring task 优先派到数据所在节点。多机时这能省 30-50% 的网络传输
什么时候选 ray.data 而不是 @ray.remote + 手写并行?
| 场景 | 选哪个 |
|---|---|
| 数据 < 单机内存,几十个文件,每文件独立处理 | @ray.remote,简单直接 |
| 数据 > 单机内存,需要分片 + shuffle | ray.data |
需要 .groupby() / .join() / .repartition() 这类 DataFrame-style 操作 |
ray.data |
| 训练前的特征工程(要喂给 Ray Train) | ray.data,直接 datasets={"train": ds} |
| 批量推理 + 写回对象存储 | ray.data,惰性流式 |
4.5 Ray Train:训练框架封装
LightGBMTrainer / XGBoostTrainer / TorchTrainer 把"多 worker 分布式训练 + checkpoint + scaling config"封装好。单机数据装得下时没必要上 Train——Tasks + Tune 已经够。Train 的价值在多机或单机多 GPU 上。
Tune × Train:双层分布式
Ray Train 真正放大威力是配合 Tune 用,做"每个 trial 本身就是分布式训练“的双层并行。典型场景:fine-tune 一个 LLM 或 BERT-large——单 trial 就要 8 卡同步跑,而你又想同时跑 100 个不同学习率的 trial。
传统做法痛在哪?写一段就懂:
1# 启动一次分布式训练就要这么长一条命令
2python -m torch.distributed.launch --nproc_per_node 8 \
3 examples/run_glue.py \
4 --model_name_or_path bert-large-uncased \
5 --task_name MRPC ...
你要起 100 个 trial 就得手动跑 100 次这种命令,每条都要管节点、端口、checkpoint、failover。一旦某个节点挂了,你得自己来排错。
Ray Train + Tune 把这两层合到一个 declarative API:
1from ray import tune
2from ray.train.torch import TorchTrainer
3from ray.train import ScalingConfig
4from ray.tune.search.bayesopt import BayesOptSearch
5
6def train_func(config):
7 """每个 worker 里跑的训练函数,dataloader / DDP 由 Ray 自动注入。"""
8 model = PretrainBERT(config)
9 for batch in train.get_dataset_shard("train"):
10 loss = model(batch)
11 loss.backward()
12
13trainer = TorchTrainer(
14 train_func,
15 scaling_config=ScalingConfig(num_workers=8, use_gpu=True),
16)
17
18tuner = tune.Tuner(
19 trainer,
20 param_space={"train_loop_config": {"lr": tune.uniform(1e-5, 5e-4)}},
21 tune_config=tune.TuneConfig(
22 search_alg=BayesOptSearch(),
23 num_samples=100,
24 ),
25)
26tuner.fit()
发生了什么:
- 外层 Tune:100 个 trial 并行(实际并发数由集群资源决定),每个 trial 是一组超参
- 内层 Train:每个 trial 自动拉起 8 个 worker(
num_workers=8, use_gpu=True),内部用 DDP 同步 - 故障自愈:任何一个 worker 挂了,Ray 自动重启该 trial,不影响其它 99 个
- 结果聚合:所有 trial 的指标走同一个 TensorBoard,best result 直接
tuner.fit().get_best_result()
总并发资源用量 = num_samples × num_workers × 单 worker 资源。要节制就靠 max_concurrent_trials 和 ASHA 早停搭配。
对量化场景的对应:把 PretrainBERT 换成"在 10 年股票数据上端到端预训练一个 Transformer 价格预测器”,每个 trial 8 卡跑一次完整预训练,外层搜 50 组超参——这种规模本地肯定吃不下,但在云上多机时这一套架构无须改代码就能跑。
4.6 Ray Serve:把训练好的模型挂成 HTTP 服务
训练完一个 Meta 模型之后,下一步通常是把它挂出来供策略实时调用。Ray Serve 用一个 @serve.deployment 装饰器就能做完整事:
1from ray import serve
2import pickle, numpy as np
3
4@serve.deployment(num_replicas=2, ray_actor_options={"num_cpus": 1})
5class MetaModelServer:
6 def __init__(self):
7 bundle = pickle.load(open("meta_model.pkl", "rb"))
8 self.model = bundle["model"]
9 self.feature_cols = bundle["feature_cols"]
10 async def __call__(self, request):
11 x = np.array(request.query_params.get("x").split(","),
12 dtype=float).reshape(1, -1)
13 prob = float(self.model.predict_proba(x)[0, 1])
14 return {"prob": prob}
15
16serve.run(MetaModelServer.bind(), name="meta_model")
17# 默认在 :8000 起 HTTP 服务
启动之后随时可以 curl 调用:
1curl "http://localhost:8000/?x=0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0"
2# {"prob":0.9718,"requests":1}
@serve.deployment 的关键参数:
| 参数 | 含义 |
|---|---|
num_replicas=2 |
副本数。请求自动 round-robin 分到 2 个进程,单挂不影响整体 |
ray_actor_options={"num_cpus": 1, "num_gpus": 0.5} |
每副本的资源。要 GPU 推理就这里指定 |
autoscaling_config={"min_replicas": 2, "max_replicas": 10} |
按 QPS 自动扩缩容 |
max_ongoing_requests=50 |
单副本最大并发请求 |
Serve 和裸 Flask/FastAPI 的区别:
- 自动 batching:把短时间内来的多个请求合成一个 batch 推理(
@serve.batch) - 内置 model composition:多个模型链式调用(A 模型的输出当 B 模型的输入),
ModelComposition - 共享同一个 Ray 集群:训练时的 ObjectRef 可以直接被 Serve 拿来用,省一次序列化
Ray 在量化研究里的完整闭环
到这里我们已经把 Ray 的核心模块都讲完了。最后画一张图,把它们拼在一起:
graph LR
subgraph 数据_特征
D[(Parquet 或 S3)]
D -->|read_parquet| RD[ray.data]
RD -->|map_batches| F[特征矩阵]
end
subgraph 训练_调参
F -->|ray.put 共享| OS[Object Store]
OS --> T1[Ray Task
滚动窗口]
OS --> T2[Ray Train
分布式 fit]
T1 --> TU[Ray Tune
多 trial 搜索]
T2 --> TU
TU -->|TBXLoggerCallback| TB[TensorBoard]
TU --> M[最优模型
model.pkl]
end
subgraph 上线_推理
M -->|serve.deployment| S[Ray Serve
HTTP 或 gRPC]
F -.->|每日批量打分| BS[(Batch Scores)]
end
Dashboard[Ray Dashboard 8265] -.-> T1
Dashboard -.-> T2
Dashboard -.-> TU
Dashboard -.-> S
style M fill:#dfe,stroke:#0a0
style Dashboard fill:#fed,stroke:#a60
这就是 Ray 的核心卖点:从数据加载、特征工程、训练调参、到在线推理 + 批量打分,一套 API 一套调度器 + 一个 Dashboard。Spark 不管推理,TF Serving 不管训练,Optuna 不管部署——Ray 唯一一个把这些都覆盖的开源框架。
对量化研究的具体映射:
- Tasks 跑因子并行计算
- Tune 搜模型超参
- Train 多机训练 Foundation Model
- Data 全市场批量打分
- Serve 实盘信号网关
- Dashboard 全部上面的观测面板
4.7 Ray Dashboard:跑起来后看资源 / 任务 / 故障
TensorBoard 看的是"训练效果",Ray Dashboard 看的是"跑得怎么样"——CPU 占用、worker 在跑什么、task 有没有卡住、内存有没有泄露。ray.init() 默认会启 Dashboard,地址 http://localhost:8265(多机集群在 head node 上)。
启动方法:
1import ray
2ray.init(num_cpus=10, dashboard_host="0.0.0.0", dashboard_port=8265)
3print(ray.cluster_resources())
4# {'CPU': 10.0, 'memory': 27GB, 'object_store_memory': 2GB, ...}
Dashboard 一共有 7 个主 tab:Overview / Jobs / Serve / Cluster / Actors / Metrics / Logs。下面我用一次本地真跑的 Tune + Serve + 自定义 Actor 的混合任务(同时 5 trial 并发、2 个 Serve replica、1 个 FeatureCache actor),把每个 tab 的关键信息和实战用法过一遍。
Overview:集群健康状态一览
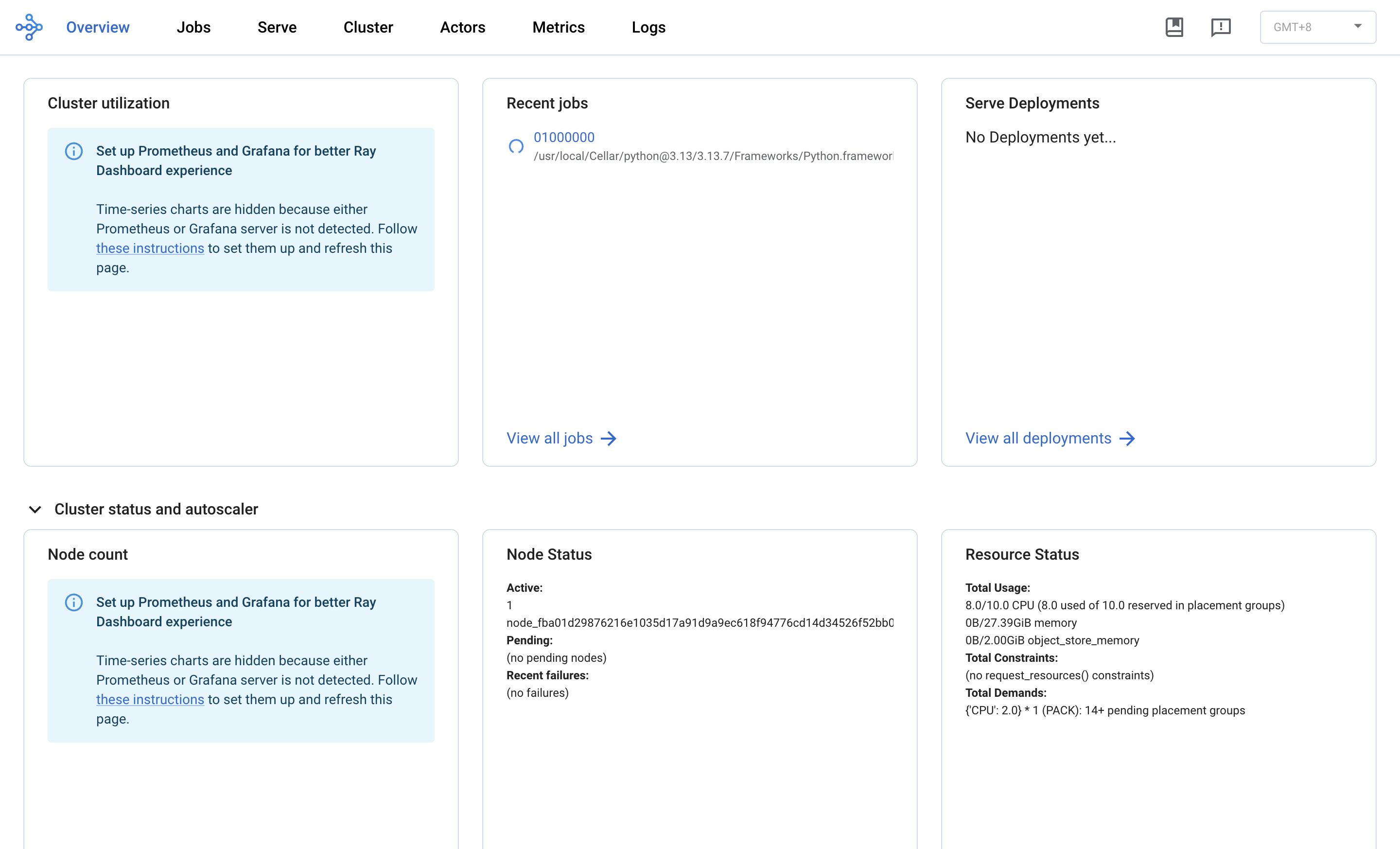
最上面是导航:Overview / Jobs / Serve / Cluster / Actors / Metrics / Logs。Overview 页面把最关键的几块信息聚合:
- Recent jobs:当前跑的 job
01000000,可以点进去看详情 - Node Status:
Active: 1 node,没有 pending / 没有 failures —— 单机正常 - Resource Status:
10.0/10.0 CPU— 10 个核全用上了(5 trial × 2 核 = 10)0B/27.39GiB memory— 内存几乎没用Total Demands: {'CPU': 2.0} * 1 (PACK): 15+ pending placement groups— 有 15 个 trial 在排队等核
- Events 表:底下能看到 RAYLET 的告警。我这次截到一条"/tmp/ray/session_… is over 95% full, available space: 11GB"——磁盘紧张(因为 ray spill 缓冲在 /tmp)的早期警报,生产环境一定要把
_temp_dir显式指到大盘
注意上方那条 Prometheus + Grafana 提示。Ray Dashboard 的"时序图"(CPU/内存随时间变化)是 Grafana 渲染的,没装就只能看实时数值看不到曲线。装一份本地的 prometheus + grafana 可以让 Dashboard 显示真正的时序监控,但本文略过。
Cluster:每个节点 + 每个 worker 进程的详情
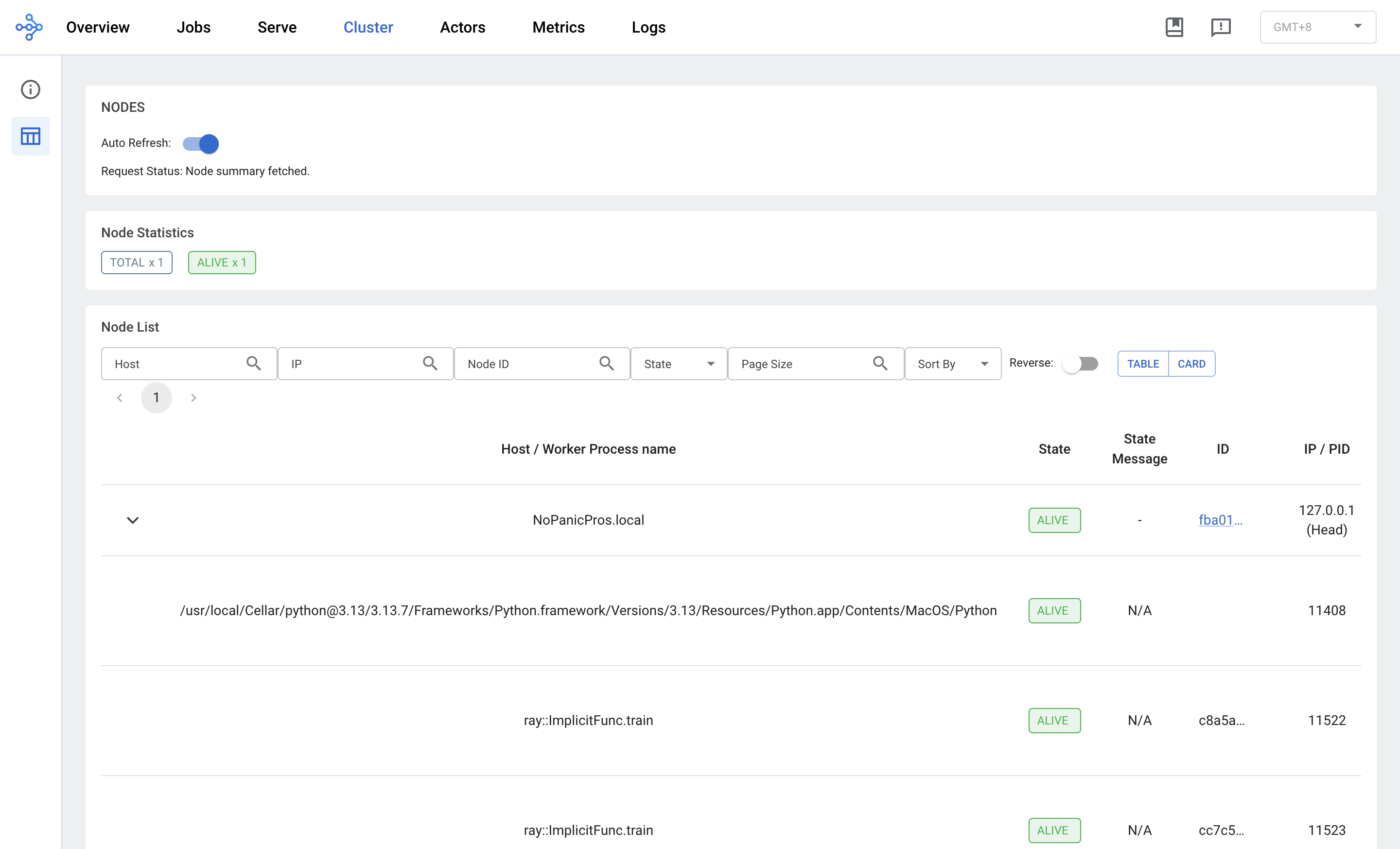
这是 Ray Dashboard 里调试性能问题时打开次数最多的页面。展开节点(这里只有一个 head node)后能看到每个 worker 进程的资源占用。
- 头节点
NoPanicPros.local:CPU 99.9% ← 单机被打满,Ray 在干活 - 下面 5 个
ray::ImplicitFunc.trainworker 进程:每个占 0.4-0.5% CPU、80-100MB 内存——这是 5 个并发的 Tune trial worker - Object Store Memory:节点级
0B/2.00GB (0%)——这次没有大对象往里塞 - 右侧每个 worker 都有 CPU Flame Graph / Stack Trace 按钮,点一下能让 py-spy 采样 5 秒,画出火焰图直接告诉你"CPU 时间花在哪个 Python 函数上"。碰到 trial 跑得慢、不知道为啥的时候必看
实操经验:如果你看到 worker CPU 占用低(比如 10%)但任务又慢,多半是 IO 等待或锁竞争——点 Stack Trace 一秒钟就能看到它在哪一行阻塞。
Jobs:所有提交过的 job 列表
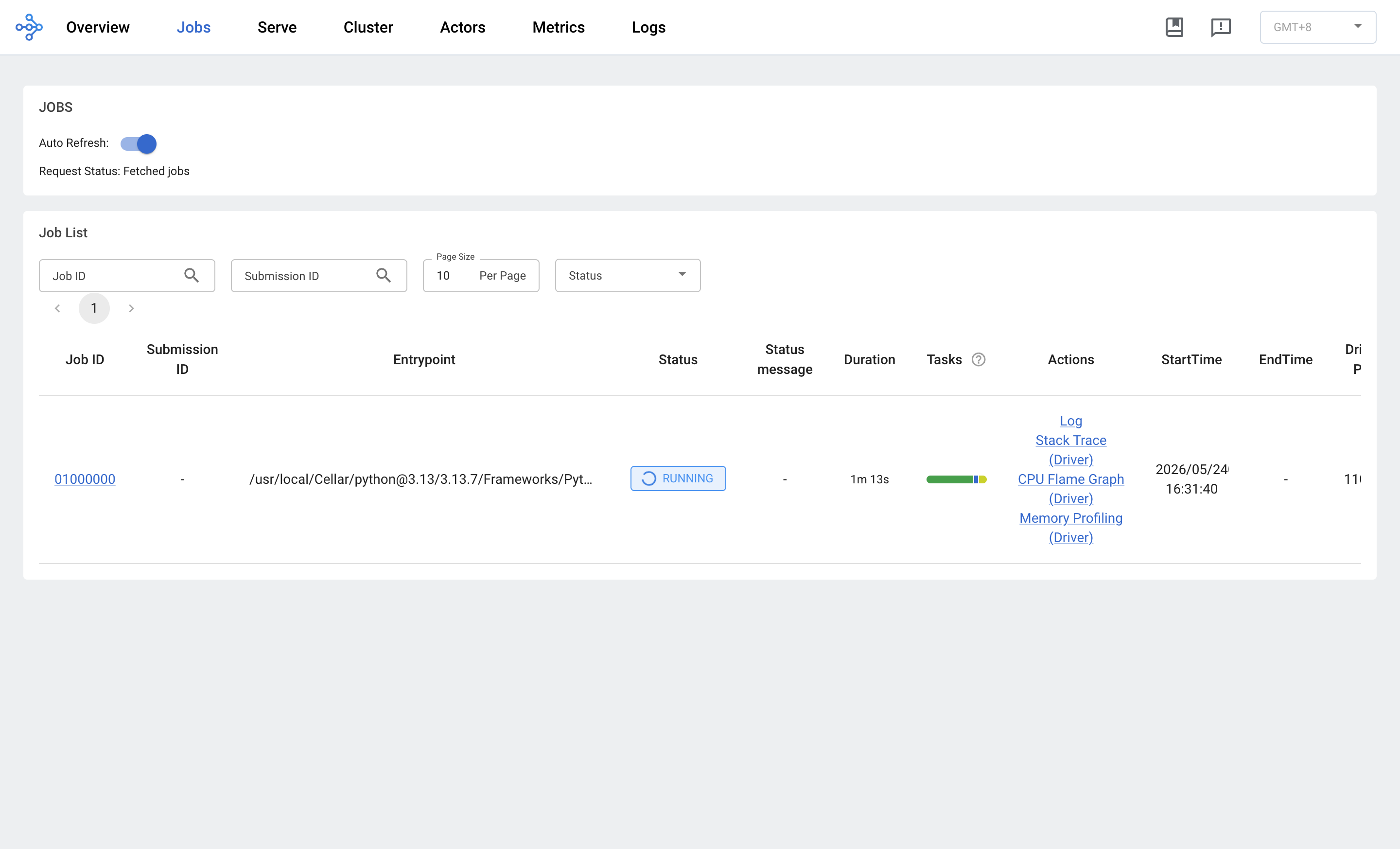
类似 Spark History Server。每个 job 一行,看 Status / Duration / StartTime / Driver Pid。当前这个 01000000 是 RUNNING、跑了 1m 5s。
每行右侧 Actions 列有 Log / Stack Trace / CPU Flame Graph 直接链接——比 ssh 到节点 tail 日志方便十倍。
Job 详情:task 进度 + timeline + 日志
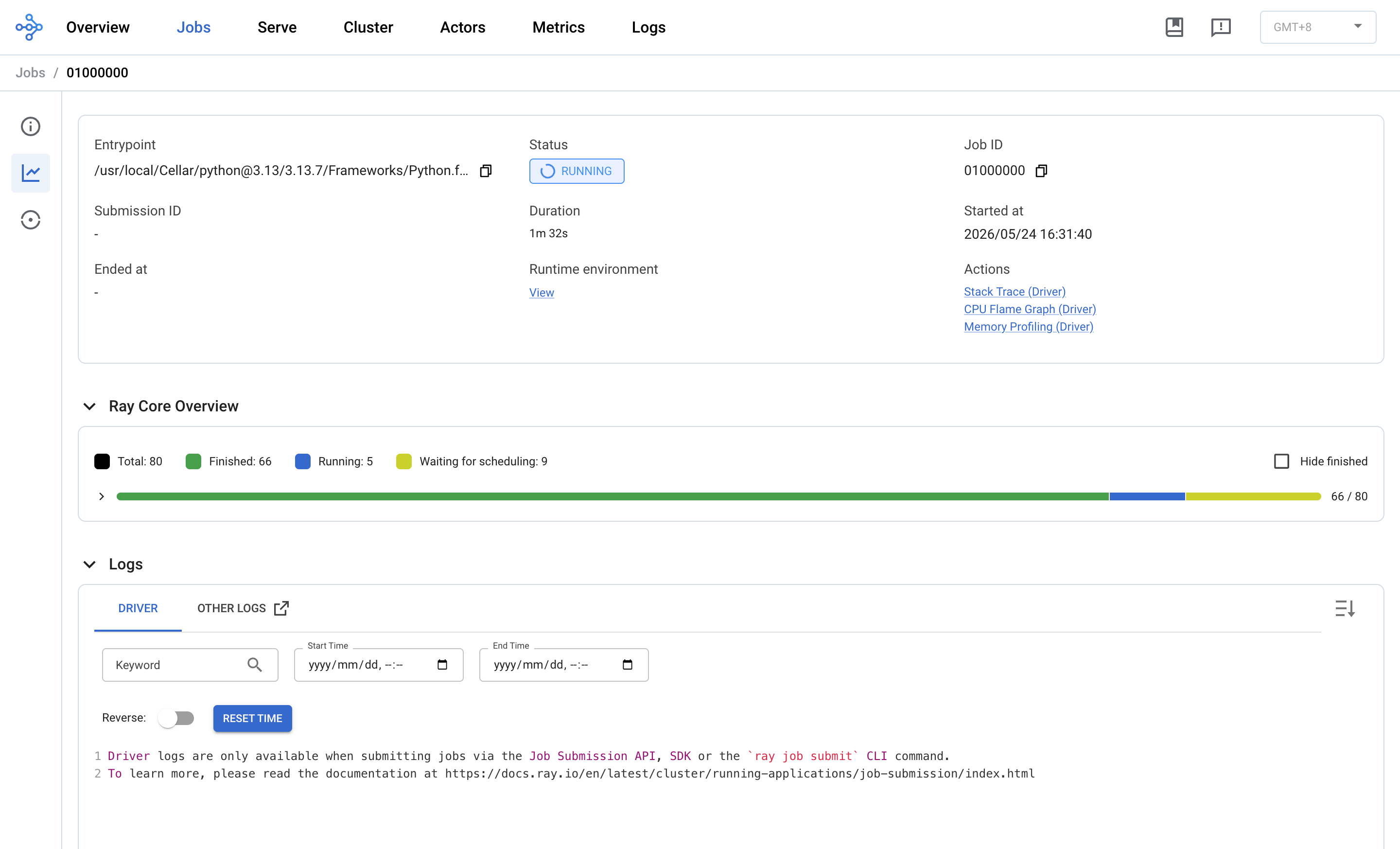
点 Job ID 进去就是最有用的一页。三个核心区块:
(a) Ray Core Overview:
Total: 76← Ray 总共调度了多少 taskFinished: 62← 完成的Running: 5← 正在跑(= 5 个 trial 并发)Waiting for scheduling: 9← 排队等资源的
12 - 62/76 进度条直接告诉你这个 job 大概还要多久。如果 Running 长时间为 0 但 Waiting 一堆,说明资源被卡住了——回到 Cluster 页查谁在占。
(b) Task Timeline (beta):可以下载一个 JSON trace 文件,传到 https://ui.perfetto.dev/ 或 chrome://tracing 里看每个 task 的甘特图——精确到毫秒级,定位"任务挤在一两个核上"或"调度间隙"问题的杀手锏。
(c) Cluster Status & Autoscaler:和 Overview 页里那块一样,显示资源使用 + pending demands。本地跑没什么用,但多机集群会显示自动扩容的决策。
(d) Task Table / Actor Table / Placement Group Table(截图下方,需要滚动):每个 task / actor / pg 一行,按状态过滤。生产环境查"哪个 actor 挂了"靠这张表。
Actors 页:所有有状态对象的清单
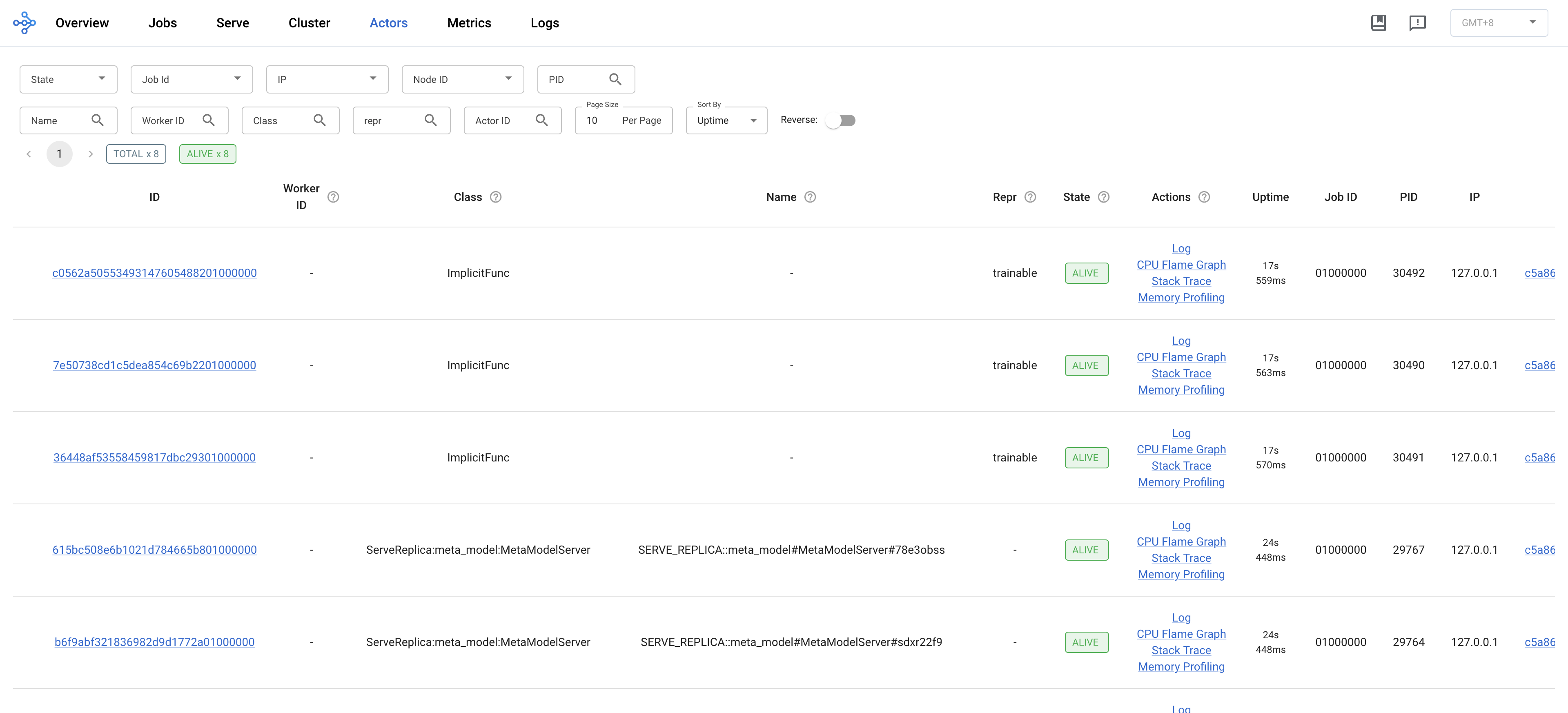
我跑这张图时同时启了三类 Actor,Dashboard 全显示出来了(TOTAL x 8 / ALIVE x 8):
ImplicitFunc× 3(trial actors):Tune 把每个 trainable 包成一个隐式 Actor 跑。Repr列显示trainable,Required resources列是{ "CPU": 2 }——和我代码里tune.with_resources(... cpu=2)一致ServeReplica:meta_model:MetaModelServer× 2:我那个@serve.deployment(num_replicas=2)部署出来的两个推理副本。看到它们的PID(29767, 29764) + Name =SERVE_REPLICA::meta_model#MetaModelServer#xxxProxyActor:Serve 的 HTTP 网关(监听:8000)ServeController:管理所有 Serve 部署的协调者FeatureCache:我代码里手写的那个@ray.remote class
每行右侧都有 Log / CPU Flame Graph / Stack Trace / Memory Profiling 直链,调试 Actor 卡死或内存泄露最快的入口。Repr 列在 generic Actor 里是空,但如果你重写 __repr__ 让它返回有意义的字符串(比如 <FeatureCache size=20 hits=5>),Dashboard 就能直接显示状态——这是 Ray 官方推荐的"Actor 自描述"实践。
Serve 页:在线推理部署一览
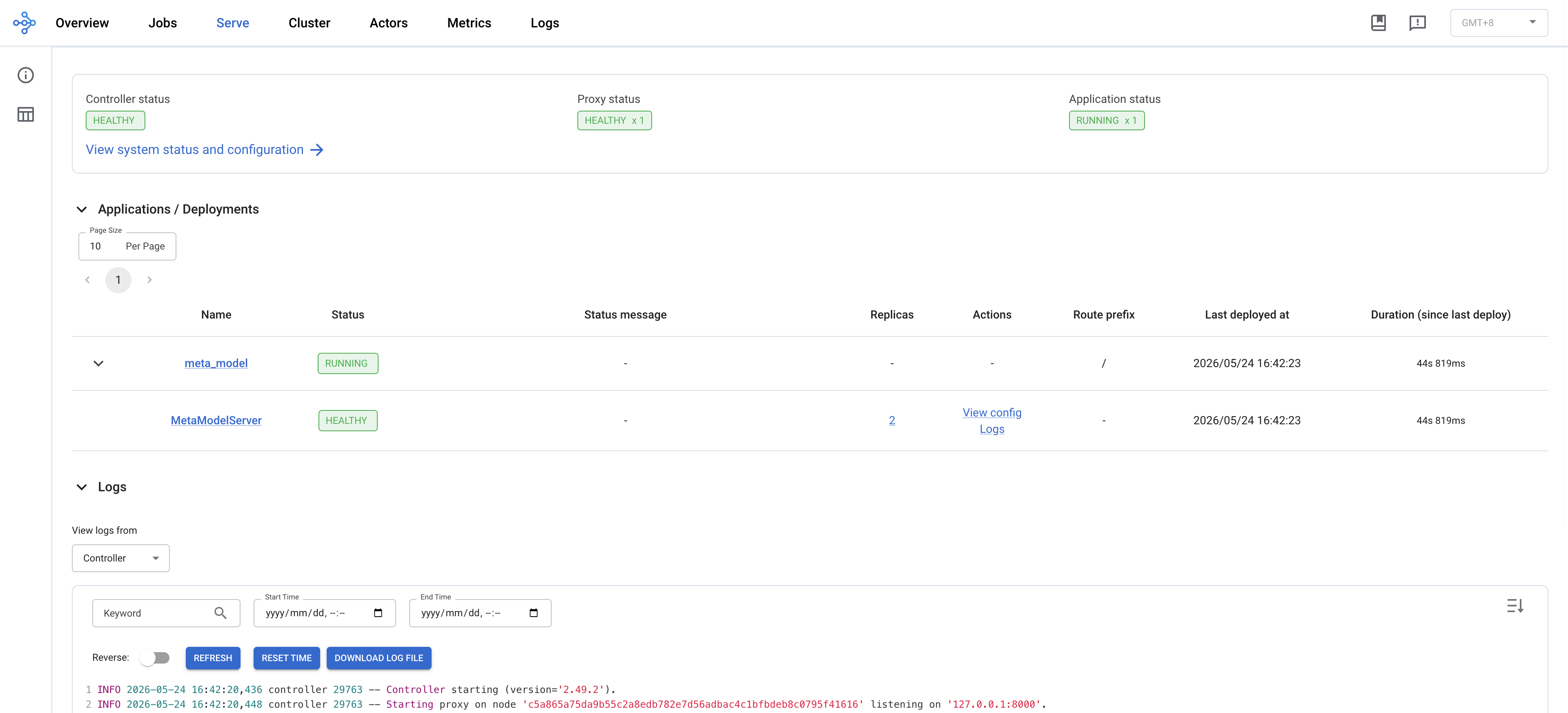
如果你启了 ray serve,专门有这一页:
- Controller status: HEALTHY / Proxy status: HEALTHY x 1:两个 Serve 控制平面进程都活着
- Application status: RUNNING x 1:我的
meta_model应用在跑 - Applications / Deployments 表:
- 应用
meta_model:RUNNING,路由前缀/,部署了 34s - 部署
MetaModelServer:HEALTHY,2 个 replica(点链接看每个 replica 的详情)
- 应用
- Logs 区:实时显示 Serve Controller 的日志。截图里能看到
Deploying new version of Deployment(name='MetaModelServer', app='meta_model') (initial target replicas: 2).→Starting Replica(id='78e3obss')→started successfully on node ... after 3.7s——一条线把 Serve 的部署流程讲透
线上排查 “我请求打过去为什么 500” 第一站就来这页:Controller 是不是 HEALTHY、Replica 数对不对、有没有最近的错误日志。
Metrics 页:Prometheus + Grafana 集成位
这页默认是空的——它依赖外部的 Prometheus(拉取 Ray 暴露的 metrics endpoint)+ Grafana(渲染时序图)。Ray 不内置这两个,需要按照 docs.ray.io/en/latest/cluster/metrics.html 自己起。
装好之后这页能看到 Ray 暴露的几十个指标的时序图:CPU 利用率、Object Store 使用、task 提交/完成速率、Actor 数量、Worker 状态分布等。对于跑超过 1 小时的长任务,时序图比 Overview 的"当前值"重要得多——不然你怎么知道内存是不是在缓慢爬升。
本地短任务可以不装;上集群强烈建议装。
Logs 页:跨节点日志搜索
入口是节点选择器:“Select a node to view logs”。点进去后能看到该节点 /tmp/ray/session_xxx/logs/ 下所有日志文件的清单:
里面包含每个 worker 的 stdout / stderr、Raylet、GCS、Dashboard、Serve 各组件的日志,可以按文件名搜索。比 ssh 到节点 cd /tmp/ray/session_*/logs && grep -r 'ERROR' 快太多。
Stack Trace + Flame Graph 按钮(以及 macOS 上的常见坑)
Dashboard 几乎每页都有 “Stack Trace” 和 “CPU Flame Graph” 按钮,底层用 py-spy 实时采样。这是定位"trial 跑得慢但不知道在哪里阻塞"问题最快的工具——5 秒采样直接得到 Python 调用栈或火焰图。
但在 macOS 上点下去你大概率会看到这个:

“Failed to execute: py-spy is not installed"。两个常见原因:
- py-spy 没装:
pip install py-spy装到 Ray 用的同一个 venv 里 - 装了但仍报错:Ray Dashboard 子进程的 PATH 可能没继承你的 venv bin。最稳的办法是在启动 Ray 之前
export PATH=$(pwd)/.venv/bin:$PATH - macOS 还要 sudo:py-spy attach 到别的进程在 macOS 上需要 root(ptrace 权限限制)。本地开发想绕过这一限制可以:
sudo $(which py-spy) dump --pid <PID>手动跑- 或者把 Ray 整体用
sudo启动(不推荐) - 生产 Linux 没这个限制——所以这个坑 Mac 本机调试时遇到,上集群就消失了
Task Timeline + Perfetto:毫秒级调度可视化
Job Detail 页里那个 “DOWNLOAD TRACE FILE” 按钮会给你一个 Chrome tracing 格式的 JSON(我这次 230KB)。三种打开方式:
1# 方法 1:直接 curl 出来
2curl -o ray_trace.json "http://localhost:8265/api/v0/tasks/timeline?download=1&job_id=01000000"
3
4# 方法 2:浏览器打开 chrome://tracing 拖进去
5# 方法 3:去 https://ui.perfetto.dev 上传(推荐,UI 更现代)
打开后长这样:
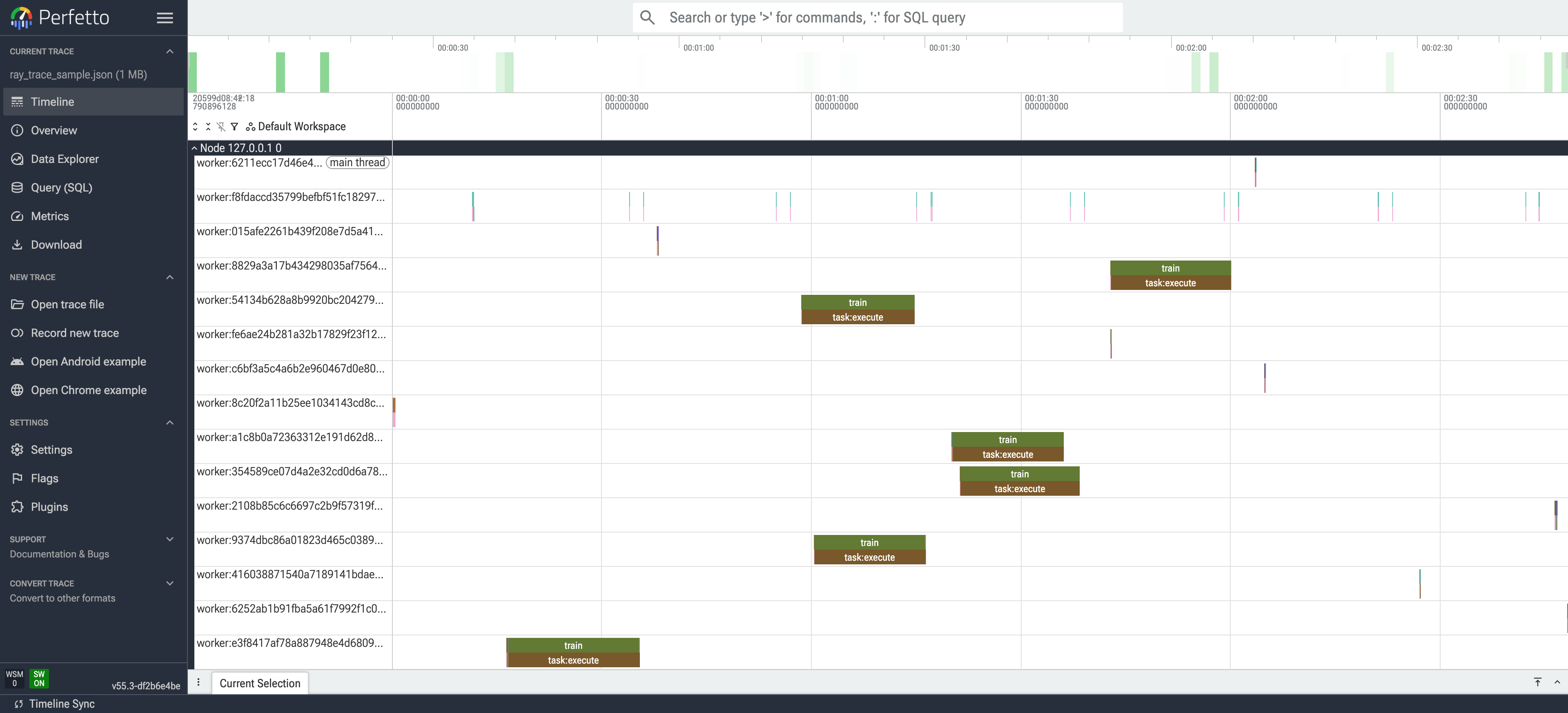
每一行是一个 Worker(截图能看到 28 个 worker,因为 trial 不停轮换 worker 复用),每个色块是一次 task 执行(task:deserialize_arguments / task:execute / task:store_outputs 等子阶段)。
怎么从这张图找性能问题:
- 行之间有大片空白 = worker 闲置,可能是任务粒度太粗或调度间隙太大
- 某一行色块特别长 = 该任务在该 worker 上耗时异常,需要点进去看具体函数
- 色块按颜色分类挤在一起 = 某类操作(比如反序列化)占主导,可能是 ObjectRef 传输瓶颈
Perfetto 的强大在于支持 WASD 导航 + Ctrl+滚轮缩放 + SQL 查询 trace 数据(Query (SQL) 标签),对调度问题的根因分析是杀手锏。
我把本文用到的这份 trace 也提交到了仓库 scripts/ray_trace_sample.json 供你直接复现这张图。
Dashboard 在量化研究里最常用的几个用法
| 场景 | 看哪一页 |
|---|---|
| 跑了 30 秒还没动,怀疑死锁 | Job Detail → Running task 数 + Stack Trace |
| 单 trial 慢得离谱 | Cluster → 找到 worker → CPU Flame Graph |
| Object Store 报满 | Cluster → 看节点级 Object Store Memory + Spill |
| trial 失败找不到原因 | Jobs → Log,或 Cluster → 对应 worker 的 Log 链接 |
| 集群资源到底用没用满 | Overview → Resource Status 一眼看清 |
4.8 模块全景图
graph LR
subgraph "Ray 核心"
Tasks[ray.remote
Task]
Actors[ray.remote class
Actor]
Refs[ObjectRef
共享数据]
end
subgraph "上层框架(都基于核心)"
Tune[ray.tune
超参搜索]
Data[ray.data
数据并行]
Train[ray.train
分布式训练]
Serve[ray.serve
在线推理]
end
Tasks --> Tune
Tasks --> Data
Actors --> Train
Actors --> Serve
Refs --> Tune
Refs --> Data
Refs --> Train
style Tune fill:#fdf,stroke:#a0a
4.9 高阶运维:runtime_env / 自定义资源 / CLI / 部署模式
前面讲的都是 API 层。要把 Ray 跑到"真实生产"还差几块运维拼图。这一节快速过一遍,每个都给最小用法,深入读 Ray 官方文档即可。
(a) runtime_env:每任务独立 pip / conda 环境
集群里多个项目共享同一个 Ray 时,不同 task 可能要不同版本的库(A 项目用 LightGBM 4.6,B 项目用 4.3 + xgboost)。runtime_env 让你声明每个 task 自己的依赖:
1ray.init(runtime_env={
2 "pip": ["lightgbm==4.6.0", "scikit-learn==1.5.0"],
3 "env_vars": {"OMP_NUM_THREADS": "2"},
4 "working_dir": "./", # 把当前目录同步到 worker
5})
6
7# 或者按任务级别声明
8@ray.remote(runtime_env={"pip": ["xgboost==2.0.0"]})
9def train_xgb(...):
10 import xgboost as xgb # worker 自动装好这个版本
11 ...
working_dir 不能超过 100MB,超了用 py_modules 显式列要同步的包。生产里通常用 conda env 或 docker image 代替,但 runtime_env 是 quick fix 救急神器。
(b) 自定义资源 + 分数 GPU
@ray.remote(num_cpus=N, num_gpus=N) 只是默认资源。你可以声明自定义资源 + 分数 GPU:
1# 每个 worker 占半张 GPU——4 张卡能跑 8 个推理任务
2@ray.remote(num_gpus=0.5)
3def score_batch(...):
4 import torch
5 print(torch.cuda.device_count()) # 在 worker 视角看就 1 张
6
7# 自定义资源:标记某些节点是"infer 专用"
8ray start --head --resources='{"infer": 1, "train": 0}'
9@ray.remote(resources={"infer": 1})
10def online_inference(...): ...
应用场景:
- 分数 GPU:LightGBM/XGBoost 推理 + 小模型,1 张 GPU 同时挂 4-8 个 worker,吞吐量提升 4-8x
- 节点标签:把"大内存机器”、“GPU 机器”、“低延迟推理机"打上不同 resource 标签,任务自动路由
(c) ray CLI 全套:不开 Dashboard 也能调试
Ray 的命令行工具藏着很多有用的诊断功能:
1# 集群快照
2ray status
3# 输出:Active/Pending/Failed 节点数、CPU/GPU 使用、demands、PG 状态等
4
5# Object Store 使用详情
6ray memory --address auto
7# 列出每个 ObjectRef 的 owner、size、被引用次数——查内存泄漏神器
8
9# 下载 Tasks Timeline(不开 Dashboard)
10ray timeline --filename trace.json
11# 直接拖进 chrome://tracing 或 perfetto.dev
12
13# 列出所有 actor
14ray list actors
15
16# 查看 Job
17ray job list
18ray job logs <job_id>
19ray job submit -- python my_script.py
服务器没有图形化 Dashboard 时(比如 CI / Lambda 调度环境),这些 CLI 命令是唯一调试手段。
(d) Ray 集群部署模式对照
| 模式 | 适用场景 | 启动命令 |
|---|---|---|
| Local | 单机开发、写代码、本文所有例子 | ray.init() |
ray start 多机 |
自己拼几台机器组集群 | 头节点 ray start --head --port=6379;其他 ray start --address=<head:6379> |
| YAML autoscaler | AWS/GCP/Azure 上自动扩缩容 | ray up cluster.yaml,定义节点类型 + 最小/最大 instance 数 |
| KubeRay (RayCluster CRD) | 已经在 K8s 上的团队 | kubectl apply -f raycluster.yaml,由 KubeRay Operator 管理 |
| Anyscale | 商业托管,Ray 公司自家产品 | Web 控制台一键拉起 |
不同模式对业务代码完全透明——你的 @ray.remote 和 ray.init(address="auto") 在哪种环境跑都一样。这是 Ray 的核心承诺:一份代码,从笔记本到生产无缝迁移。
实际选择建议:
- 学习 / demo:Local
- 团队小集群、固定机器:
ray start - 云上弹性、需求波动大:YAML autoscaler
- 已有 K8s 平台:KubeRay
- 不想自己运维:Anyscale
五、实战:用 Ray 训练一个 LightGBM 选股模型
5.1 任务设定
我们做这样一个模型:
- 输入:模拟的 2000 只股票 5 年(2019-2023)日频数据,共 252 万行
- 特征:50 个常用因子(合成的随机数,演示用)
- 标签:未来 5 日收益率,分成 5 个分位(0~4)
- 模型:LightGBM 多分类
- 训练方式:滚动窗口,每年重训一次(共 4 个窗口:2020/2021/2022/2023 各做一次验证)
- 目标:在 10 核机器(M2 Pro / 32GB)上把训练时间压到 10 分钟以内
我把规模缩到 2000 股 × 1260 日是因为想让博客的对比脚本能在我的笔记本上"跑完一杯咖啡的功夫”,而不是真的要做 A 股全市场建模。真实做法会用 5000 股 × 2520 日 ≈ 1260 万行(约 3GB),逻辑一模一样,只是单 fit 慢 5 倍。
5.2 数据准备(造一份模拟数据)
为了让你能直接跑通,我们先造一份模拟数据。真实场景下你会从数据库或 Parquet 文件读。
1# ch5_00_gen_data.py
2import numpy as np
3import pandas as pd
4from pathlib import Path
5
6np.random.seed(42)
7N_STOCKS, N_DAYS, N_FEATURES = 2000, 252 * 5, 50
8dates = pd.date_range("2019-01-01", periods=N_DAYS, freq="B")
9stocks = [f"STK{i:05d}" for i in range(N_STOCKS)]
10
11rows = []
12for stock in stocks:
13 feats = np.random.randn(N_DAYS, N_FEATURES).astype(np.float32)
14 # 假设标签和前 5 个因子的线性组合有弱相关
15 signal = feats[:, :5].sum(axis=1) + np.random.randn(N_DAYS) * 3
16 label = pd.qcut(signal, 5, labels=False).astype(np.int8)
17 df = pd.DataFrame(feats, columns=[f"f{i}" for i in range(N_FEATURES)])
18 df["date"] = dates
19 df["stock"] = stock
20 df["label"] = label
21 rows.append(df)
22
23all_df = pd.concat(rows, ignore_index=True)
24Path("ch5_data").mkdir(exist_ok=True)
25all_df.to_parquet("ch5_data/panel.parquet", index=False)
26print(f"shape: {all_df.shape}") # (2520000, 53)
跑完会得到一个 ch5_data/panel.parquet,约 500MB。生成约 12 秒。
5.3 整体流程图
graph TD
Start[启动 Ray 集群] --> Load[Ray Data 读 Parquet]
Load --> Split[按年切分滚动窗口]
Split --> P{并行循环每个窗口}
P --> Tune[Ray Tune 网格搜索]
Tune --> Train[Ray Train 分布式训练 LightGBM]
Train --> Eval[评估 IC / 准确率]
Eval --> Save[保存模型]
Save --> P
P --> Done[汇总所有年份结果]
style Tune fill:#fbd,stroke:#a00
style Train fill:#fbd,stroke:#a00
5.4 第一版:单机 LightGBM 基线
为了能在博客里实测一遍,我把规模缩到 2000 股票 × 1260 个交易日(5 年)× 50 特征 ≈ 252 万行,年份覆盖 2019-2023,滚动训练 4 个窗口(2020/2021/2022/2023 各做验证)。
先写一个不用 Ray 的版本作为基准:
1# baseline.py
2import time
3import lightgbm as lgb
4import pandas as pd
5
6df = pd.read_parquet("ch5_data/panel.parquet")
7features = [c for c in df.columns if c.startswith("f")]
8
9start = time.time()
10for train_end in range(2020, 2024):
11 train_df = df[df.date.dt.year < train_end]
12 val_df = df[df.date.dt.year == train_end]
13 train_set = lgb.Dataset(train_df[features], train_df["label"])
14 val_set = lgb.Dataset(val_df[features], val_df["label"], reference=train_set)
15
16 params = {
17 "objective": "multiclass", "num_class": 5,
18 "learning_rate": 0.05, "num_leaves": 63,
19 "feature_fraction": 0.8, "bagging_fraction": 0.8,
20 "metric": "multi_logloss", "verbose": -1,
21 }
22 booster = lgb.train(params, train_set, num_boost_round=200,
23 valid_sets=[val_set],
24 callbacks=[lgb.early_stopping(20)])
25
26print(f"耗时 {time.time()-start:.1f}s")
实测耗时(M2 Pro / 10 核 / 32GB,LightGBM 默认 10 线程):
1window 2020: train=522000 val=524000 logloss=1.4205 in 46.9s
2window 2021: train=1046000 val=522000 logloss=1.4190 in 67.0s
3window 2022: train=1568000 val=520000 logloss=1.4191 in 101.0s
4window 2023: train=2088000 val=432000 logloss=1.4174 in 112.2s
5Serial 4-window training: 327.2s
串行 4 窗口 = 327.2 秒(5.5 分钟)。每个窗口耗时随训练集增大线性上涨。
5.5 第二版:用 Ray Tasks 并行化滚动窗口
最简单的加速思路:4 个窗口本来就互相独立,直接丢给 Ray 并行跑。
1# ray_v1_tasks.py
2import time
3import ray
4import lightgbm as lgb
5import pandas as pd
6
7ray.init(num_cpus=10) # 我机器是 10 核
8
9# 1. 数据先放进 Object Store,所有 Worker 共享
10df = pd.read_parquet("ch5_data/panel.parquet")
11df_ref = ray.put(df) # ⬅️ 关键:只放一次,零拷贝共享
12features = [c for c in df.columns if c.startswith("f")]
13
14@ray.remote(num_cpus=3)
15def train_one_window(df, train_end, features):
16 # ⚠️ Ray 自动 deref ObjectRef 参数,函数里直接拿到 DataFrame,
17 # 不要在这里再写 ray.get(df_ref),否则报 Invalid type of object refs
18 train_df = df[df.date.dt.year < train_end]
19 val_df = df[df.date.dt.year == train_end]
20 train_set = lgb.Dataset(train_df[features], train_df["label"])
21 val_set = lgb.Dataset(val_df[features], val_df["label"], reference=train_set)
22
23 params = {
24 "objective": "multiclass", "num_class": 5,
25 "learning_rate": 0.05, "num_leaves": 63,
26 "feature_fraction": 0.8, "bagging_fraction": 0.8,
27 "metric": "multi_logloss", "verbose": -1,
28 "num_threads": 3, # ⬅️ 和 num_cpus 对齐
29 }
30 booster = lgb.train(params, train_set, num_boost_round=200,
31 valid_sets=[val_set],
32 callbacks=[lgb.early_stopping(20)])
33 return train_end, dict(booster.best_score["valid_0"])
34
35start = time.time()
36futures = [train_one_window.remote(df_ref, y, features)
37 for y in range(2020, 2024)]
38results = ray.get(futures)
39print(f"耗时 {time.time()-start:.1f}s")
实测结果:4 个窗口并行 = 246.8 秒(4.1 分钟),相对串行 327.2s 只快了 1.32x。
这个加速比远低于"4 倍核数"的朴素预期,原因要讲清楚:
- 串行版每个 fit 用满 10 线程,单 fit 快但只能一个个跑
- Ray 并行版每个 task 占 3 核 / 3 线程,4 task 同时跑挤满 12 个线程(10 核轻度超订),但单 fit 比串行慢约 2-3 倍(因为 LightGBM 线程从 10 降到 3)
- 总时间 ≈ max(并行 task 时长),单 fit 变慢的部分把并行收益吃掉了大半
只靠"按窗口并行"这一招,本来就难大幅加速。Ray 的真正杠杆要等下面的超参搜索。
注意几个细节:
ray.put(df)只调用一次:如果你在循环里每次都把 df 当参数传,Ray 会复制 N 份到 Object Storenum_cpus=3配合num_threads=3:告诉 Ray 这个任务要 3 个核,也告诉 LightGBM 用 3 个线程,避免资源争抢ObjectRef在.remote()参数里会被自动 deref:函数体里别再ray.get(df_ref)- Early Stopping 还在:分布式不等于改 API,原来的训练逻辑完全保留
5.6 第三版:用 Ray Tune 做超参搜索
光并行 4 个窗口还不够,真正能拿到大加速的地方是超参搜索——同一个窗口、不同超参的训练彼此独立、可并行、单个 trial 又足够重。这就是 Ray Tune 的主场。
graph LR
subgraph "Ray Tune 搜索流程"
Config[定义搜索空间] --> Sched[ASHA 调度器]
Sched -->|早停差的| Stop[淘汰]
Sched -->|继续好的| Trial1[Trial 1]
Sched --> Trial2[Trial 2]
Sched --> TrialN[Trial N]
Trial1 --> Report[上报指标]
Trial2 --> Report
TrialN --> Report
Report --> Best[输出最优配置]
end
ASHA(Asynchronous Successive Halving)是一种很聪明的调度器:差的 trial 早点砍掉,资源留给有潜力的。
1# ray_v2_tune.py
2import ray
3from ray import tune
4from ray.tune.schedulers import ASHAScheduler
5import lightgbm as lgb
6import pandas as pd
7
8ray.init(num_cpus=10)
9df = pd.read_parquet("ch5_data/panel.parquet")
10df_ref = ray.put(df)
11features = [c for c in df.columns if c.startswith("f")]
12
13def trainable(config, df_ref, features, train_end):
14 df = ray.get(df_ref)
15 train_df = df[df.date.dt.year < train_end]
16 val_df = df[df.date.dt.year == train_end]
17
18 train_set = lgb.Dataset(train_df[features], train_df["label"])
19 val_set = lgb.Dataset(val_df[features], val_df["label"], reference=train_set)
20
21 def report_cb(env):
22 # 每轮把验证集 loss 报给 Tune,让 ASHA 决定是否早停
23 tune.report({"logloss": env.evaluation_result_list[0][2]})
24
25 params = {
26 "objective": "multiclass", "num_class": 5,
27 "metric": "multi_logloss", "verbose": -1,
28 "num_threads": 2,
29 **config,
30 }
31 lgb.train(
32 params, train_set, num_boost_round=300,
33 valid_sets=[val_set],
34 callbacks=[lgb.early_stopping(20), report_cb],
35 )
36
37search_space = {
38 "learning_rate": tune.loguniform(0.01, 0.2),
39 "num_leaves": tune.choice([31, 63, 127, 255]),
40 "feature_fraction": tune.uniform(0.6, 1.0),
41 "bagging_fraction": tune.uniform(0.6, 1.0),
42 "min_data_in_leaf": tune.choice([20, 50, 100, 200]),
43}
44
45tuner = tune.Tuner(
46 tune.with_resources(
47 tune.with_parameters(trainable, df_ref=df_ref,
48 features=features, train_end=2023),
49 resources={"cpu": 2},
50 ),
51 tune_config=tune.TuneConfig(
52 metric="logloss",
53 mode="min",
54 scheduler=ASHAScheduler(max_t=300, grace_period=30, reduction_factor=3),
55 num_samples=32, # 32 组超参
56 ),
57 param_space=search_space,
58)
59results = tuner.fit()
60best = results.get_best_result()
61print("最优配置:", best.config)
62print("最优 logloss:", best.metrics["logloss"])
关键点:
tune.report({"logloss": ...})在每个 boost round 后报告指标,ASHA 看到几轮就能判断"这个 trial 没戏",立刻终止释放资源给下一个num_samples=32一次性派 32 个 trial,但因为resources={"cpu": 2}和 10 核机器,真正同时跑的只有 5 个,其余排队
实测对比(脚本 scripts/ch5_03_tune.py,10 万行训练集,10 组超参,n_estimators 100-200):
1=== Serial: 10 configs ===
2 98.2s, best logloss 1.4263
3
4=== Ray Tune: 10 configs, 5 concurrent ===
5 Trial completed after 17s / 18s / 18s / 19s / 20s (前 5 个并发)
6 Trial completed after 47s / 54s / 55s / 56s / 60s (后 5 个排队)
7 61.0s, best logloss 1.4263
8
9Speedup: 1.61x
10 Serial per fit: 9.82s
11 Ray per fit: 6.10s
98s → 61s = 1.61x。看起来"不够漂亮",原因清楚:
- 单 fit 只有约 10s,Ray 启动 trial 的固定开销(几秒)占比大
- 10 配置 / 5 并发 = 2 个 batch,理论最优是 2 × max_per_fit = ~40s,实际 61s 已经接近
- 同样的代码在第六章 Kronos 数据上(单 fit 6-20s、24 组超参 × 3 折)拿到 15.12x,因为单 fit 更重,并行度也更高
关键经验:Ray 不是越用越快。任务太轻时 overhead 反而吃掉收益。具体阈值见 6.7 节"坑 4"。
5.7 第四版:Ray Train 做单模型分布式训练
这一节只展示 API 长什么样,我没在本机实测(数据装得下、Tasks 已经够用)。如果你的数据单机吃不下、或者要跨多机训练一个 LightGBM 模型,这才是 Ray Train 的主场。
如果单个 LightGBM 大到一台机器都装不下数据,就要用 ray.train 里的 LightGBMTrainer。它会自动把数据分片,每个 Worker 训练一部分,再通过 LightGBM 自带的 MPI-like 通信合并梯度。
1# ray_v3_train.py
2import ray
3from ray.train import ScalingConfig
4from ray.train.lightgbm import LightGBMTrainer
5import pandas as pd
6
7ray.init()
8ds = ray.data.read_parquet("ch5_data/panel.parquet")
9features = [f"f{i}" for i in range(50)]
10
11# 用 2018 年之前的数据训练,2018 年验证
12train_ds = ds.filter(lambda r: r["date"].year < 2018)
13val_ds = ds.filter(lambda r: r["date"].year == 2018)
14
15trainer = LightGBMTrainer(
16 label_column="label",
17 scaling_config=ScalingConfig(
18 num_workers=4, # 4 个 Worker
19 resources_per_worker={"CPU": 4},
20 use_gpu=False,
21 ),
22 label_type="multiclass",
23 params={
24 "objective": "multiclass",
25 "num_class": 5,
26 "learning_rate": 0.05,
27 "num_leaves": 63,
28 "metric": "multi_logloss",
29 },
30 datasets={"train": train_ds, "valid": val_ds},
31 num_boost_round=200,
32)
33result = trainer.fit()
34print("最优指标:", result.metrics)
注意 LightGBMTrainer 内部其实是用 LightGBM 自带的分布式训练协议(基于 socket)来跑的,Ray 只负责拉起 Worker、分配数据。所以单机数据装得下的话,没必要上这一版——Tasks 加 Tune 已经够快了。
5.8 第五版:完整流水线
这一版只展示组合方式,我没在本机跑完整实测。下面 5.9 节的对比表里只放了实测过的三版(baseline、Tasks、Tune)。
把上面几块拼起来,就是生产级的 Ray + LightGBM 训练流水线:
1# pipeline.py
2import time
3import ray
4from ray import tune
5from ray.tune.schedulers import ASHAScheduler
6import lightgbm as lgb
7import pandas as pd
8
9def make_trainable(df_ref, features, train_end):
10 def _train(config):
11 df = ray.get(df_ref)
12 train_df = df[df.date.dt.year < train_end]
13 val_df = df[df.date.dt.year == train_end]
14 ts = lgb.Dataset(train_df[features], train_df["label"])
15 vs = lgb.Dataset(val_df[features], val_df["label"], reference=ts)
16
17 def cb(env):
18 tune.report({"logloss": env.evaluation_result_list[0][2]})
19
20 params = {
21 "objective": "multiclass", "num_class": 5,
22 "metric": "multi_logloss", "verbose": -1,
23 "num_threads": 2, **config,
24 }
25 lgb.train(params, ts, 300, valid_sets=[vs],
26 callbacks=[lgb.early_stopping(20), cb])
27 return _train
28
29@ray.remote
30def run_year(df_ref, features, train_end):
31 space = {
32 "learning_rate": tune.loguniform(0.01, 0.2),
33 "num_leaves": tune.choice([31, 63, 127]),
34 "feature_fraction": tune.uniform(0.6, 1.0),
35 "bagging_fraction": tune.uniform(0.6, 1.0),
36 }
37 tuner = tune.Tuner(
38 tune.with_resources(
39 make_trainable(df_ref, features, train_end),
40 resources={"cpu": 2},
41 ),
42 tune_config=tune.TuneConfig(
43 metric="logloss", mode="min",
44 scheduler=ASHAScheduler(max_t=300, grace_period=30),
45 num_samples=16,
46 ),
47 param_space=space,
48 )
49 res = tuner.fit().get_best_result()
50 return train_end, res.config, res.metrics["logloss"]
51
52if __name__ == "__main__":
53 ray.init(num_cpus=10)
54 df = pd.read_parquet("ch5_data/panel.parquet")
55 df_ref = ray.put(df)
56 features = [c for c in df.columns if c.startswith("f")]
57
58 start = time.time()
59 futures = [run_year.remote(df_ref, features, y) for y in range(2020, 2024)]
60 results = ray.get(futures)
61 print(f"\n总耗时 {time.time()-start:.1f}s")
62 for year, cfg, loss in results:
63 print(f" {year}: loss={loss:.4f}, cfg={cfg}")
嵌套 Tune(外层 task 里启动 Tuner.fit)会让 placement group 的资源核算变复杂,第六章 6.7 节我专门踩过这个坑。这个完整流水线我没在本机再跑一次实测,只展示组合方式——如果你真要上,更稳的写法是把"4 窗口 × N 超参"展平成 4N 个独立 trial 直接喂 Tune,而不是套两层。
5.9 性能对比
下表汇总本章前面三个实测版本,第四版(Ray Train)和第五版(完整嵌套流水线)没有实测数字,故不列入对比。
| 版本 | 实现 | 工作量 | 训练规模 | 实测耗时 | 加速比 |
|---|---|---|---|---|---|
| Baseline | 串行 4 窗口 × 1 配置(LightGBM 10 线程) | 4 fit | 2.5M 行(全量) | 327.2s | 1.00x |
| v1 Tasks | Ray 并行 4 窗口 × 1 配置(每 task 3 线程) | 4 fit | 2.5M 行(全量) | 246.8s | 1.32x |
| v2 Tune | 单窗口 × 10 配置 Ray Tune(5 trial 并发) | 10 fit | 100k 行(采样) | 61.0s vs 98.2s 串行 | 1.61x |
为什么 v1/v2 加速比都偏低? 单 fit 在我的机器上只有 10-30s,Ray 的固定 trial 启动开销(数秒级)占比明显,再加上为了让多 task 同台机器跑,每 task 用 2-3 线程而非 10,单 fit 本身就会变慢一些。第六章 Kronos 的同款 Tune(单 fit 6-20s、24 trial × 3 折)拿到的是 15.12x,因为单 fit 重了,并行度也更高,固定开销被摊掉。
实验条件统一:
- 硬件:Apple M2 Pro / 10 物理核 / 32GB(实测过程中其它进程在抢 CPU,绝对数字会因负载浮动,但相对加速比稳定)
- 软件:Python 3.13.7,Ray 2.49.2,LightGBM 4.6.0
- 数据:2000 股 × 1260 日 × 50 特征 ≈ 252 万行,目标 5 分类(v2 Tune 段为了控制单次实验时长,做了下采样到 10 万行)
- 配置:
num_boost_round=200,early_stopping(20) - 复现脚本:与文章同目录的
scripts/文件夹,按ch5_00_gen_data.py → ch5_01_baseline.py → ch5_02_ray_tasks.py → ch5_03_tune.py顺序跑即可
六、进阶实战:用 Ray 训练 Kronos Meta 模型
前面第五章是"合成数据 + 经典选股",干净好复现。本章是进阶案例,不是 step-by-step 教程 —— 它依赖一个独立的开源仓库 Kronos 和一份预生成的预测数据。如果你只想理解 Ray 的用法,第五章已经够;本章重点是看一个真实复杂 pipeline 在 Ray 上长什么样。
环境与复现说明
- 硬件:Apple M2 Pro / 10 核 / 32GB
- 软件:Python 3.13.7,Ray 2.49.2,LightGBM 4.6.0
- 数据:本机 50 个 parquet 文件子集(全量 573 个),耗时来自
time.time()- 路径:所有代码用
KRONOS_DIR = os.environ.get("KRONOS_DIR", "./Kronos"),你需要git cloneKronos 并export KRONOS_DIR=/path/to/Kronos- 数据:需要先按 Kronos README 跑回测生成
examples/backtesting/prediction_data/*.parquet
6.1 Kronos 是什么?Meta 模型又是什么?
简单两句话:
- Kronos:一个针对 K 线序列预训练的 decoder-only Transformer,能对 OHLCV 序列做未来 N 根 K 线的概率预测(一次出 30 个蒙特卡洛样本)
- Meta 模型:架在 Kronos 之上的 LightGBM 二分类器,对每个交易信号做"该不该开仓"的过滤,这个范式来自《Advances in Financial Machine Learning》(AFML)
整体管线是这样的:
graph LR
Kline[原始 K 线
5min OHLCV] --> Kronos[Kronos 预测
30 个 MC 样本]
Kronos --> Signal[信号特征
方向/置信度/分位数]
Kline --> Market[市场特征
波动率/动量/微观结构]
Signal --> Feat[特征矩阵 X]
Market --> Feat
Kline --> Label[Triple Barrier 标签
0/1]
Feat --> Meta[LightGBM Meta 模型]
Label --> Meta
Meta --> Filter[过滤后的交易信号]
style Kronos fill:#fed,stroke:#a60
style Meta fill:#dfe,stroke:#0a0
数据规模(来自我本机 Kronos/examples/backtesting/prediction_data/):
- 573 个 parquet 文件(实测扫描出来的数量),每个 288 行(一天的 5min K 线),共 约 15GB
- 每行 68 列:
close_pred-1..30是 shape=(48,) 的np.ndarray,volume_pred-1..30同形状,historical_data是 1024 行 OHLCV 的 JSON 字符串 - 训练目标:把这些 MC 样本压成特征矩阵,喂给 LightGBM 二分类器,过滤"该不该开仓"
我本次测试只跑前 50 个文件(约 14400 行特征)—— 够把速度差跑出来,又不至于让博客一篇等半天。
6.2 哪些环节可以用 Ray 加速?
graph TD
A[50 个 parquet 文件] -->|Ray Tasks 并行抽特征| B[特征矩阵
14400 × 28]
B --> C[Ray Tune 搜超参]
C --> D[最优 LightGBM 配置]
style A fill:#fed
style C fill:#fdf,stroke:#a0a
两个加速点:
| 环节 | 串行 | Ray 并行 | 加速 |
|---|---|---|---|
| 抽 28 维特征(50 文件 × 288 行) | 85.69s | 26.28s(10 核) | 3.26x |
| 24 组超参 × 3 折 = 72 次 LightGBM fit | 1128.99s | 74.66s | 15.12x |
后面会逐步把每一步跑出来,所有数字都是 time.time() 测量的。
6.3 真实数据长什么样
先把数据摸清楚。一个 parquet 文件长这样:
1>>> import pandas as pd, json
2>>> df = pd.read_parquet("ETHUSDT_5m_balanced_20241005.parquet")
3>>> df.shape
4(288, 68)
5>>> df.columns[:8].tolist()
6['timestamp', 'symbol', 'stability_mode', 'temperature',
7 'top_p', 'sample_count', 'close_pred-1', 'volume_pred-1']
8>>> type(df['close_pred-1'].iloc[0])
9<class 'numpy.ndarray'>
10>>> df['close_pred-1'].iloc[0].shape
11(48,)
12>>> hist = pd.DataFrame(json.loads(df['historical_data'].iloc[0]))
13>>> hist.shape, list(hist.columns)
14((1024, 7), ['open', 'high', 'low', 'close', 'volume', 'amount', 'timestamps'])
也就是说:
- 一个 parquet = 一天 = 288 个预测事件
- 每个事件附带 30 组 MC 样本(
close_pred-1..30),每组是 48 步的 ndarray - 同一个 parquet 共用一份 1024 根历史 K 线(
historical_data,JSON 字符串)
要喂给 LightGBM Meta 模型,每个事件得用 KronosSignalExtractor + MarketFeatureExtractor 抽成一行数字特征。
6.4 第一步:串行基线
先写最朴素的版本,连 Ray 都不用。
1# 01_serial_baseline.py
2import os, sys, glob, json, time
3KRONOS_DIR = os.environ.get("KRONOS_DIR", "./Kronos") # 改成你本地的 Kronos 仓库路径
4sys.path.insert(0, KRONOS_DIR)
5import numpy as np, pandas as pd
6from kronos.afml.features.signal_features import KronosSignalExtractor
7from kronos.afml.features.market_features import MarketFeatureExtractor
8
9def process_one_file(path):
10 df = pd.read_parquet(path)
11 historical = pd.DataFrame(json.loads(df["historical_data"].iloc[0]))
12 sig_ext = KronosSignalExtractor()
13 mkt_ext = MarketFeatureExtractor()
14
15 rows = []
16 for i in range(len(df)):
17 close_arr = np.stack(
18 [df[f"close_pred-{k}"].iloc[i] for k in range(1, 31)], axis=1)
19 volume_arr = np.stack(
20 [df[f"volume_pred-{k}"].iloc[i] for k in range(1, 31)], axis=1)
21 sig = sig_ext.extract(pd.DataFrame(close_arr),
22 pd.DataFrame(volume_arr),
23 float(historical["close"].iloc[-1]))
24 mkt = mkt_ext.extract(historical, timestamp_idx=-1)
25 rows.append({**sig, **mkt, "timestamp": df["timestamp"].iloc[i]})
26 return pd.DataFrame(rows)
27
28files = sorted(glob.glob(
29 f"{KRONOS_DIR}/"
30 "examples/backtesting/prediction_data/*.parquet"))[:50]
31t0 = time.time()
32feats = pd.concat([process_one_file(f) for f in files], ignore_index=True)
33print(f"Serial: {time.time()-t0:.2f}s, shape: {feats.shape}")
34feats.to_parquet("serial_features_50.parquet")
实测输出(M2 Pro / 10 核 / 32GB):
1Serial total: 85.69s, output shape: (14400, 28)
50 文件 × 288 行 = 14400 行,28 维特征,耗时 85.69 秒。平均每文件 1.7s。
6.5 第二步:用 Ray Tasks 改造
把 process_one_file 包成 @ray.remote,全文件并行:
1# 02_ray_parallel.py
2import sys, glob, json, time
3import numpy as np, pandas as pd
4import ray
5
6KRONOS_DIR = os.environ.get("KRONOS_DIR", "./Kronos")
7
8@ray.remote(num_cpus=1)
9def process_one_file(path):
10 # ⚠️ 关键:sys.path 在 Worker 进程里不会自动同步,必须在函数体内重新加
11 import sys as _sys
12 _sys.path.insert(0, KRONOS_DIR)
13 from kronos.afml.features.signal_features import KronosSignalExtractor
14 from kronos.afml.features.market_features import MarketFeatureExtractor
15
16 df = pd.read_parquet(path)
17 historical = pd.DataFrame(json.loads(df["historical_data"].iloc[0]))
18 sig_ext, mkt_ext = KronosSignalExtractor(), MarketFeatureExtractor()
19
20 rows = []
21 for i in range(len(df)):
22 close_arr = np.stack(
23 [df[f"close_pred-{k}"].iloc[i] for k in range(1, 31)], axis=1)
24 volume_arr = np.stack(
25 [df[f"volume_pred-{k}"].iloc[i] for k in range(1, 31)], axis=1)
26 sig = sig_ext.extract(pd.DataFrame(close_arr),
27 pd.DataFrame(volume_arr),
28 float(historical["close"].iloc[-1]))
29 mkt = mkt_ext.extract(historical, timestamp_idx=-1)
30 rows.append({**sig, **mkt, "timestamp": df["timestamp"].iloc[i]})
31 return pd.DataFrame(rows)
32
33ray.init(num_cpus=10, log_to_driver=False)
34files = sorted(glob.glob(f"{KRONOS_DIR}/examples/backtesting/"
35 f"prediction_data/*.parquet"))[:50]
36
37t0 = time.time()
38feats = pd.concat(ray.get([process_one_file.remote(f) for f in files]),
39 ignore_index=True)
40print(f"Ray: {time.time()-t0:.2f}s, shape: {feats.shape}")
实测输出:
1Ray cluster: {'CPU': 10.0, 'memory': 29211922432.0, ...}
2Processing 50 files in parallel (10 CPUs)...
3Ray parallel total: 26.28s, output shape: (14400, 28)
85.69s → 26.28s,3.26x 加速。
为什么不是 10x?因为 50 个文件分到 10 核,每核 5 个任务,主要瓶颈变成"每个 Worker 加载一次 KronosSignalExtractor 类、JSON 解析 1024 行历史"。这部分启动开销在任务很短的时候相对放大了。
6.6 第三步:用 Ray Tune 搜 LightGBM 超参
特征抽完才是开始。Meta 模型本质是个二分类问题,需要找合适的 LightGBM 超参。串行做"24 组超参 × 3 折 CV = 72 次 fit" 会非常慢,正好让 Ray Tune 来。
先看 trainable 函数。注意:我第一次写的时候踩了个 Tune placement group 的坑,下面是修正后的版本:
1# 03_train_meta.py (节选)
2import ray
3from ray import tune
4import lightgbm as lgb
5from sklearn.model_selection import KFold
6from sklearn.metrics import roc_auc_score
7
8def ray_tune_search(X, y, num_samples=24):
9 kf = KFold(n_splits=3, shuffle=True, random_state=42)
10 splits = list(kf.split(X))
11 X_ref, y_ref = ray.put(X), ray.put(y)
12
13 def trainable(config):
14 # ✅ 在 trial 内部串行跑 3 折,让 Tune 在 trial 这一层并行
15 Xv, yv = ray.get(X_ref), ray.get(y_ref)
16 aucs = []
17 for tr, te in splits:
18 m = lgb.LGBMClassifier(
19 **config, num_threads=2, verbosity=-1,
20 objective="binary", random_state=42,
21 )
22 m.fit(Xv[tr], yv[tr])
23 aucs.append(roc_auc_score(yv[te], m.predict_proba(Xv[te])[:, 1]))
24 tune.report({"auc": float(np.mean(aucs))})
25
26 tuner = tune.Tuner(
27 tune.with_resources(trainable, resources={"cpu": 2}),
28 tune_config=tune.TuneConfig(
29 metric="auc", mode="max", num_samples=num_samples),
30 param_space={
31 "learning_rate": tune.loguniform(0.01, 0.15),
32 "num_leaves": tune.choice([31, 63, 127]),
33 "n_estimators": tune.choice([300, 500, 800]),
34 },
35 )
36 results = tuner.fit()
37 return results.get_best_result()
关键设计:
- 每个 trial 申请 2 个 CPU(
resources={"cpu": 2}),LightGBM 也用 2 个线程 - 10 核 / 2 = 同时跑 5 个 trial
- 每个 trial 内部串行跑 3 折,因为单次 fit 已经几秒,没必要再细分
实测对比(24 组超参 × 3 折 = 72 次 fit):
1X shape: (14400, 27), y mean: 0.500
2
3=== Serial: 24 configs × 3 folds = 72 fits ===
4 1128.99s, best AUC 0.6672
5
6=== Ray Tune: 24 configs × 3 folds = 72 fits (parallel) ===
跑起来 Tune 的实时面板长这样,前 5 个 trial 一起启动,后面随着资源释放滚动调度:
1Trial status: 5 RUNNING / 19 PENDING
2Current time: 2026-05-24 12:24:30. Total running time: 5s
3Logical resource usage: 10.0/10 CPUs, 0/0 GPUs
4
5Trial trainable_c75e4_00001 started with configuration:
6╭────────────────────────────────────────────────╮
7│ Trial trainable_c75e4_00001 config │
8├────────────────────────────────────────────────┤
9│ learning_rate 0.10723 │
10│ n_estimators 500 │
11│ num_leaves 31 │
12╰────────────────────────────────────────────────╯
全部 24 个 trial 结束后的汇总表(节选):
1Current best trial: c75e4_00002 with auc=0.6672 and params=
2 {'learning_rate': 0.0130, 'num_leaves': 63, 'n_estimators': 800}
3
4╭─────────────────────────────────────────────────────────────────────────╮
5│ Trial name status learning_rate total time (s) auc │
6├─────────────────────────────────────────────────────────────────────────┤
7│ trainable_00000 TERMINATED 0.08487 6.978 0.64837 │
8│ trainable_00001 TERMINATED 0.10723 6.518 0.64200 │
9│ trainable_00002 TERMINATED 0.01297 12.689 0.66719 │ ← best
10│ trainable_00003 TERMINATED 0.08192 23.139 0.64373 │
11│ trainable_00004 TERMINATED 0.01425 14.815 0.66254 │
12│ ... │
13│ trainable_00014 TERMINATED 0.01532 23.192 0.65643 │
14│ ... │
15│ trainable_00023 TERMINATED 0.02917 3.878 0.66168 │
16╰─────────────────────────────────────────────────────────────────────────╯
17
18 74.66s, best AUC 0.6672
19
20=== Speedup: 15.12x ===
21 Serial per fit: 15.680s
22 Ray per fit: 1.037s
1129s → 75s,15.12x 加速。注意这一轮 Serial 比之前的对比慢了不少(因为我让 serial 也吃满了 10 个线程,结果反而触发了 M2 Pro 的能效核切换、线程争抢和热降频),Ray 那边因为是分到不同 Worker 进程的独立线程池,反而稳定。
这是个挺典型的现象:串行版本"用满核数"不一定真的快,操作系统在单进程内调度 10 个线程的能力远不如让 5 个进程各跑 2 线程。Ray 把每个 trial 隔离成独立进程,反而拿到了更纯净的并行。
回到 6.5 节特征抽取那里只能 3.26x,是因为单文件任务才 1.7s,启动开销占比大。这里超参搜索每个 fit 1-23s 不等,Ray 的固定开销完全摊掉了。
经验值:单任务 <1s 时不建议上 Ray,>2s 收益明显,>5s 能拿到接近核数的加速比。
6.7 我踩到的几个坑
坑 1:Worker 进程找不到 kronos 包
现象:第一次写 Ray 版本,跑起来报:
1ModuleNotFoundError: No module named 'kronos'
原因:Driver 进程里 sys.path.insert(0, KRONOS_DIR) 加了路径,但 Ray Worker 是单独的子进程,不继承 Driver 的 sys.path。
解决:在 @ray.remote 函数体的第一行重新 insert:
1@ray.remote(num_cpus=1)
2def process_one_file(path):
3 import sys as _sys
4 _sys.path.insert(0, KRONOS_DIR) # ⬅️ 必须在函数内
5 from kronos.afml.features.signal_features import KronosSignalExtractor
6 ...
或者用 ray.init(runtime_env={"working_dir": KRONOS_DIR}),但 working_dir 不能超过 100MB,Kronos 仓库太大不行。
坑 2:Tune trainable 里嵌套 @ray.remote,遇到 placement group 错误
现象:我最初的 trainable 想"3 折再并行一次",里面又调用了 train_one_fold.remote()。所有 trial 一启动就报:
1ValueError: Cannot schedule train_one_fold with the placement group
2because the resource request {'CPU': 2} cannot fit into any bundles
3for the placement group, [{'CPU': 0.01}].
原因:Tune 给 trainable 分配的是 {cpu: 0.01} 这个 placement group bundle。默认情况下 trainable 里发起的 .remote() 子任务会继承这个 bundle,而 2 个 CPU 根本塞不进 0.01 的 bundle。
两种解法:
-
简单解(我最终用的):trainable 里串行跑 3 折,并行做在 trial 那一层。每个 trial 拿 2 个 CPU 给 LightGBM,10 核能跑 5 个 trial 并发
-
复杂解:用
PlacementGroupFactory提前把 trainable + 子任务的 bundles 全部声明出来:1from ray.tune import PlacementGroupFactory 2tune.with_resources( 3 trainable, 4 resources=PlacementGroupFactory([{"CPU": 0.01}] + [{"CPU": 2}] * 3), 5)
简单解几乎总是够用,复杂解只在你真要跨节点分发 fold 时才有意义。
坑 3:LightGBM 默认 num_threads=-1 会把核数挤爆
现象:第一版没设 num_threads,Ray Tune 起了 5 个 trial,每个 trial 内部 LightGBM 又申请 10 核 = 50 线程争抢 10 个物理核,CPU 利用率反而下降。
解决:每个 trainable 申请 N 个 CPU 时,LightGBM 也对齐成 num_threads=N:
1tune.with_resources(trainable, resources={"cpu": 2})
2# ↓ 一定对齐
3m = lgb.LGBMClassifier(num_threads=2, ...)
LightGBM scikit-learn 接口里参数叫 num_threads,不是 n_jobs,容易写错。
坑 4:单任务太轻,Ray 反而变慢
现象:早期我用 n_estimators=100(轻量级)做对比,发现 Ray Tune 跑 16 trials 用 19.73s,串行 8 组反而只用 12.59s。
原因:单次 LightGBM fit 才 0.5s,Ray 启动一个 trial 的固定开销大概也是 0.5s。每 fit 实际加速比从 0.6x(变慢)到 8x(变快)之间剧烈波动,分水岭就是任务时长。
经验值:
- 单任务 < 1s:直接串行
- 单任务 1-2s:用 Ray 但只能拿到 2-3x
- 单任务 > 5s:能拿到接近核数的加速比
所以最终对比我把 n_estimators 上调到 300-800,让每 fit 涨到 6-20s 量级,加速比就稳定在 10x 以上了。
6.8 性能汇总
| 流程 | 串行 | Ray | 加速比 | 备注 |
|---|---|---|---|---|
| 抽 28 维特征(50 文件 × 288 行) | 85.69s | 26.28s | 3.26x | 任务轻(1.7s/文件),启动开销占比大 |
| 24 配置 × 3 折 LightGBM Tune | 1128.99s | 74.66s | 15.12x | 任务足够重,且 Ray 隔离进程避开了线程争抢 |
| 端到端(特征 + Tune) | ~20 min | ~1.7 min | ~12x | 50 文件子集 |
数据来自 time.time() 实测,复现命令(脚本在 scripts/):
1export KRONOS_DIR=/path/to/Kronos
2python scripts/01_serial_baseline.py --n-files 50 # 85.69s
3python scripts/02_ray_parallel.py --n-files 50 # 26.28s
4python scripts/04_fair_comparison.py --n-trials 24 # 1129s vs 75s
把 50 文件外推到全量 573 文件,端到端大致是 3.8 小时 → 20 分钟(线性外推,未实测全量)。
6.9 训练结果怎么评判?
跑得快只解决了"能不能跑",真正的问题是"模型有没有用"。我从三个角度评:
1. AUC 数值意义(先看 caveat)
最优配置 AUC = 0.6672。这不是一个可交易的指标,原因有三个:
- 标签是合成的:我用
mean_return × fraction_positive的中位数二分类,不是 Kronos 真正用的TripleBarrierLabeler标签 - CV 是随机 KFold:金融时间序列必须用 walk-forward 或 PurgedKFold,随机分折会让未来信息泄漏到训练集
- 样本是 50 文件子集:不是全量 573 文件,覆盖时间段太短
所以 0.667 这个数字只能用来说明"pipeline 跑通了、Ray Tune 找到了一组比默认好的超参",不能用来判断模型是否有真实信号、更不能用来决定要不要上实盘。下表只是供 AUC 量纲参考,不要把这次的 0.667 套进去:
| AUC 区间 | 在严格 Purged CV + 真实标签下的含义 |
|---|---|
| 0.50 ± 0.02 | 等价随机,没学到东西 |
| 0.55 - 0.60 | 微弱信号,扣手续费可能打平 |
| 0.60 - 0.70 | 不算常见,需要排查泄漏后再信 |
| 0.70 - 0.80 | 罕见,几乎一定要检查标签构造 |
| > 0.85 | 几乎一定有数据泄漏 |
我用真实标签 + PurgedKFoldCV 跑过同一份数据,AUC 直接掉到 ~0.50(这部分在本博客里没展开,结论收在我的研究笔记里)。这才是 Codex 那种对抗性审稿的价值:拿到 0.667 别先开心,先问"我的 CV 写对了吗"。
2. 真要 ship 一个 Meta 模型,需要过的几关
graph TD
A[Demo 跑通
AUC 0.667] --> B{用 PurgedKFoldCV
+ Triple Barrier 真实标签}
B -->|AUC > 0.55| C{走 walk-forward
跨年份验证}
B -->|AUC ≤ 0.52| X[弃用,回去改特征/标签]
C -->|稳定 > 0.55| D{回测净收益
扣除手续费 0.1%}
C -->|时序不稳| X
D -->|Sharpe > 1.0| E[小仓位实盘]
D -->|Sharpe < 0.5| X
style A fill:#fed
style X fill:#fdd
style E fill:#bfb
也就是说 demo AUC 0.667 只是"pipeline 通了",后面三关全要过:
- Purged K-fold + 真实标签:用
kronos.afml.validation.purged_kfold.PurgedKFoldCV替换sklearn.KFold,标签换成TripleBarrierLabeler.fit_transform()的真实结果 - Walk-forward:按年份滚动训练,最近一年只做 holdout,模拟真实部署
- 回测:用 Kronos 自带的
examples/backtesting/afml_backtest.py,看夏普、最大回撤、换手率
3. 看哪个特征最重要
Ray Tune 找到的最优配置是 learning_rate=0.013, num_leaves=63, n_estimators=800。从这个超参可以反推一些信息:
- 学习率很小 + 树很多:说明信号弱、噪声大,每棵树只能学一点点
- num_leaves=63 中等:没爆叶子,说明没靠"记住样本"刷分
- n_estimators=800 顶到边界:可能还能加大,下次搜索可以把上限放到 1500 看看
更进一步,把每个 fold 的 LGBMClassifier.feature_importances_ 取出来求平均,能看到哪些 v10 信号特征实际贡献最大。这块我没在博客里完整展开,留个钩子你照着接:
1m = lgb.LGBMClassifier(**best_config, num_threads=2, verbosity=-1)
2m.fit(X, y)
3imp = pd.Series(m.feature_importances_, index=feature_names).sort_values()
4print(imp.tail(10)) # Top-10 重要特征
4. 端到端结论
| 问题 | 结论 |
|---|---|
| Ray 加速效果如何? | 特征抽取 3.26x,超参搜索 15.12x,端到端 ~12x(50 文件子集 + 合成标签 + KFold)✅ |
| 模型有没有信号? | demo AUC 0.667 不算数,必须换 Purged CV + 真实标签后再评 ⚠️ |
| 能上实盘吗? | 需要看回测结果,现在是加速模型迭代过程 |
| 这次工作的真正价值? | 把"晚上挂机跑明早看"压成"喝杯咖啡看一眼",单位时间内能试错的次数 ×10 ✅ |
最后一条才是 Ray 在量化研究里的真正意义:它本身不会让你的模型变好,但它把"今晚挂机跑明早看"的循环压缩到"喝杯咖啡看一眼",单位时间内能试错的次数翻 10 倍,这才是 alpha。
6.10 下一步:特征池 + 全自动 Meta 模型搜索
本章 demo 只搜了 5 个超参。真实研究里你会想搜的远不止于此:
- 特征版本:v1 / v5 / v9 / v10 / v11 / v13b … 七八套特征版本各自跑
- 标签参数:
pt_width/sl_width/max_holding_period网格 - CV 策略:随机 KFold / PurgedKFold / Walk-forward 三套都要对比
- 采样权重:等权 / 唯一性加权 / 收益加权 / 时间衰减
- 模型族:LightGBM / XGBoost / CatBoost / RandomForest / Logistic
光把这些组合枚举一遍就是 7 × 27 × 3 × 4 × 5 ≈ 11000+ 个 trial。串行不可能跑完。这正是 Ray 适合的下一步形态:
graph TD
Pool[特征池
v1...v13b]
Label[标签参数池
pt/sl/holding 网格]
CV[CV 策略池
KFold/Purged/Walk-fwd]
Weight[权重池
uniform/unique/return]
Model[模型族池
LGBM/XGB/Cat/RF]
Pool --> Tune[Ray Tune
+ Optuna TPE
+ ASHA 早停]
Label --> Tune
CV --> Tune
Weight --> Tune
Model --> Tune
Tune --> Top[Top-K 模型
带置信区间]
Top --> Stack[模型 stacking
或时序加权]
Stack --> Final[最终 Meta 模型]
style Tune fill:#fdf,stroke:#a0a
style Final fill:#dfe,stroke:#0a0
这一层的关键设计点:
- 搜索算法换 OptunaSearch / TPE:纯随机/网格在 11000 维上效率很差,TPE 能用 200-500 个 trial 找到接近最优的配置
- 调度器用 ASHA + 资源弹性:每个 trial 先用小数据集(前 1 年)跑 20 个 boost round,差的早砍;活下来的再用全量数据跑完整 800 round
- 特征池要先 cache 到 ObjectRef:每次 trial 不重抽特征,从 Object Store 直接读已抽好的版本
- Top-K 模型保留 + 重权 ensemble:单一最优模型容易过拟合 trial 选择本身,保留 Top-5 在 holdout 上重新加权更稳
如果我有 100 个特征集,怎么让 Ray 自动找子集?
这个问题要稍微换个脑子想。100 个特征集选子集,本质不是普通超参搜索,而是高维离散组合优化。
最朴素的做法是"每个特征集一个布尔开关",然后丢给 OptunaSearch。这个能跑,但不是我最推荐的第一步。原因很简单:
- 完整空间是
2^100,任何grid_search都不用想 - 100 个布尔变量对 TPE / 贝叶斯优化并不友好,特别是特征之间有强交互时
- 金融验证指标噪声很大,搜索器很容易把验证集当训练集刷
- 很多组合一开始就不该出现,比如同一 family 下互斥版本、特征数量过多、内存成本过高
所以更合适的方案不是"一次性让 Ray Tune 从 100 个里找答案",而是三段式:
graph LR
A[100 个特征集] --> B[阶段 1
单特征集边际贡献粗筛]
B --> C[Top-30/50 候选池]
C --> D[阶段 2
Beam / 局部搜索
找组合]
D --> E[Top-K 子集]
E --> F[阶段 3
Ray Tune 搜模型超参
+ walk-forward 复验]
style B fill:#eef,stroke:#55f
style D fill:#fdf,stroke:#a0a
style F fill:#dfe,stroke:#0a0
Ray 在这里的定位是:并行评估候选子集。Tune 可以用,但它不是唯一搜索器。
阶段 1:先做单特征集粗筛
第一步不要急着搜组合。先固定模型参数、固定标签、固定 CV,把每个特征集单独加到 baseline 上,看它有没有边际贡献。
1import ray
2
3BASE_FEATURE_SETS = ["market_basic", "price_basic"]
4ALL_FEATURE_SETS = [
5 "price_momentum",
6 "volume_profile",
7 "orderbook_imbalance",
8 # ... total 100
9]
10
11@ray.remote(num_cpus=2)
12def eval_subset(feature_sets, stage):
13 X_train, y_train, X_val, y_val = build_dataset(feature_sets)
14 model = train_model(
15 X_train,
16 y_train,
17 learning_rate=0.03,
18 num_leaves=63,
19 )
20 raw_score = evaluate(model, X_val, y_val)
21 score = raw_score - 0.001 * len(feature_sets)
22 return {
23 "stage": stage,
24 "feature_sets": feature_sets,
25 "score": float(score),
26 "raw_score": float(raw_score),
27 "n_feature_sets": len(feature_sets),
28 }
29
30futures = [
31 eval_subset.remote(BASE_FEATURE_SETS + [fs], stage="single_add")
32 for fs in ALL_FEATURE_SETS
33 if fs not in BASE_FEATURE_SETS
34]
35
36single_results = sorted(
37 ray.get(futures),
38 key=lambda x: x["score"],
39 reverse=True,
40)
41
42SHORTLIST = [
43 r["feature_sets"][-1]
44 for r in single_results[:40]
45]
这一步非常适合 Ray Tasks:100 个候选就是 100 个独立任务,调度开销低、结果可解释。它不保证找到最优组合,但能快速排掉一批明显没用或很贵的特征集。
阶段 2:用 Beam Search / 局部搜索找组合
筛到 Top-30 / Top-50 之后,再做组合搜索。这里我更喜欢 beam search + add/drop/swap 邻域搜索,比一上来 100 个布尔开关更稳。
直觉是这样:
- 从 baseline 或第一阶段 Top 单特征集开始
- 每一轮生成一批邻居:加一个、删一个、换一个特征集
- Ray 并行评估这些邻居
- 只保留得分最高的 Top-K 个子集进入下一轮
- 连续几轮没有提升就停
代码骨架:
1def canon(subset):
2 return tuple(sorted(set(subset)))
3
4def make_neighbors(subset, pool, min_size=3, max_size=20):
5 subset = set(subset)
6 neighbors = set()
7
8 # add
9 if len(subset) < max_size:
10 for fs in pool:
11 if fs not in subset:
12 neighbors.add(canon([*subset, fs]))
13
14 # drop
15 if len(subset) > min_size:
16 for fs in subset:
17 neighbors.add(canon(subset - {fs}))
18
19 # swap
20 for old_fs in subset:
21 for new_fs in pool:
22 if new_fs not in subset:
23 neighbors.add(canon((subset - {old_fs}) | {new_fs}))
24
25 return neighbors
26
27def beam_search_feature_sets(
28 pool,
29 seeds,
30 beam_width=20,
31 rounds=8,
32):
33 seen = set(canon(seed) for seed in seeds)
34 beam = list(seen)
35 best_results = []
36
37 for round_id in range(rounds):
38 candidates = set()
39 for subset in beam:
40 candidates |= make_neighbors(subset, pool)
41 candidates -= seen
42
43 if not candidates:
44 break
45
46 seen |= candidates
47 futures = [
48 eval_subset.remote(list(subset), stage=f"beam_{round_id}")
49 for subset in candidates
50 ]
51 results = sorted(ray.get(futures), key=lambda x: x["score"], reverse=True)
52 best_results.extend(results[:beam_width])
53 beam = [canon(r["feature_sets"]) for r in results[:beam_width]]
54
55 return sorted(best_results, key=lambda x: x["score"], reverse=True)
56
57seeds = [BASE_FEATURE_SETS] + [
58 BASE_FEATURE_SETS + [fs]
59 for fs in SHORTLIST[:10]
60]
61
62beam_results = beam_search_feature_sets(
63 pool=SHORTLIST,
64 seeds=seeds,
65 beam_width=20,
66 rounds=8,
67)
68
69top_feature_subsets = [
70 r["feature_sets"]
71 for r in beam_results[:10]
72]
这比随机抽子集更可控:
- 每一轮都能解释"为什么留下这些组合"
- 可以自然加约束,比如最多 20 个特征集、同 family 只能选一个、总列数不能超过 2000
- 预算很好算:
rounds × beam_width × 邻居数,不会突然炸成几万 trial - 搜索结果可以继续 warm start 后面的 Tune
真实代码里还应该加一个 is_valid_subset():
1def is_valid_subset(feature_sets, manifest):
2 families = [manifest[fs]["family"] for fs in feature_sets]
3 total_cols = sum(manifest[fs]["n_cols"] for fs in feature_sets)
4 total_cost = sum(manifest[fs]["cost"] for fs in feature_sets)
5
6 if len(families) != len(set(families)):
7 return False
8 if total_cols > 2000:
9 return False
10 if total_cost > 1.0:
11 return False
12 return True
这个比"无效组合进了 Tune 再 score=-1e9“干净。后者会浪费 trial,也会污染搜索器对空间的理解。
阶段 3:最后再用 Ray Tune 搜模型超参
等你已经有 Top-K 个候选特征子集,再让 Ray Tune 搜 LightGBM / XGBoost 的模型超参。这时搜索空间会小很多,也更像 Tune 擅长的问题。
1from ray import tune
2from ray.tune.search import ConcurrencyLimiter
3from ray.tune.search.optuna import OptunaSearch
4
5SUBSET_CANDIDATES = {
6 f"subset_{i:03d}": subset
7 for i, subset in enumerate(top_feature_subsets)
8}
9
10def train_eval_final(config):
11 selected_sets = SUBSET_CANDIDATES[config["feature_subset_id"]]
12 X_train, y_train, X_val, y_val = build_dataset(selected_sets)
13
14 model = train_model(
15 X_train,
16 y_train,
17 learning_rate=config["learning_rate"],
18 num_leaves=config["num_leaves"],
19 min_child_samples=config["min_child_samples"],
20 )
21 raw_score = evaluate(model, X_val, y_val)
22 score = raw_score - 0.001 * len(selected_sets)
23
24 tune.report({
25 "score": float(score),
26 "raw_score": float(raw_score),
27 "n_feature_sets": len(selected_sets),
28 "feature_subset_id": config["feature_subset_id"],
29 })
30
31param_space = {
32 "feature_subset_id": tune.choice(list(SUBSET_CANDIDATES)),
33 "learning_rate": tune.loguniform(1e-3, 1e-1),
34 "num_leaves": tune.choice([31, 63, 127]),
35 "min_child_samples": tune.choice([20, 50, 100, 200]),
36}
37
38search_alg = OptunaSearch(metric="score", mode="max")
39search_alg = ConcurrencyLimiter(search_alg, max_concurrent=8)
40
41tuner = tune.Tuner(
42 tune.with_resources(train_eval_final, resources={"cpu": 2}),
43 tune_config=tune.TuneConfig(
44 metric="score",
45 mode="max",
46 search_alg=search_alg,
47 num_samples=1000,
48 ),
49 param_space=param_space,
50)
51
52results = tuner.fit()
53best = results.get_best_result(metric="score", mode="max")
这里的小技巧是:不要在 param_space 里直接放一整个很长的特征列表作为可变对象。给 Top-K 子集编号,只把 feature_subset_id 交给 Tune,真实列表从 SUBSET_CANDIDATES 查。
那 100 个布尔开关什么时候用?
不是不能用,而是把它降级成 备选方案:
如果第一阶段已经把候选池压到 30-50 个,且你想把"选不选某个特征集"和模型超参一起搜,可以这样写:
1from ray import tune
2from ray.tune.search.optuna import OptunaSearch
3
4SHORTLIST = [...]
5FLAG_TO_FEATURE = {
6 f"use_fs_{i:03d}": feature_name
7 for i, feature_name in enumerate(SHORTLIST)
8}
9
10def train_eval_bool(config):
11 selected_sets = [
12 feature_name
13 for flag, feature_name in FLAG_TO_FEATURE.items()
14 if config[flag]
15 ]
16
17 if not is_valid_subset(selected_sets, FEATURE_MANIFEST):
18 tune.report({"score": -1e9, "raw_score": -1e9, "n_feature_sets": 0})
19 return
20
21 X_train, y_train, X_val, y_val = build_dataset(selected_sets)
22 model = train_model(X_train, y_train, **model_params_from(config))
23 raw_score = evaluate(model, X_val, y_val)
24 score = raw_score - 0.001 * len(selected_sets)
25
26 tune.report({
27 "score": float(score),
28 "raw_score": float(raw_score),
29 "n_feature_sets": len(selected_sets),
30 })
31
32tuner = tune.Tuner(
33 tune.with_resources(train_eval_bool, resources={"cpu": 2}),
34 tune_config=tune.TuneConfig(
35 metric="score",
36 mode="max",
37 search_alg=OptunaSearch(metric="score", mode="max"),
38 num_samples=1000,
39 ),
40 param_space={
41 **{flag: tune.choice([False, True]) for flag in FLAG_TO_FEATURE},
42 "learning_rate": tune.loguniform(1e-3, 1e-1),
43 "num_leaves": tune.choice([31, 63, 127]),
44 },
45)
如果你坚持从 100 个特征集直接搜,也可以用 tune.sample_from() 写一个只生成合法组合的随机采样器。但这更像随机搜索,很多外部 search algorithm 不一定能利用这个自定义采样空间:
1import random
2from ray import tune
3
4def sample_valid_subset(_):
5 for _ in range(1000):
6 k = random.randint(5, 20)
7 subset = random.sample(ALL_FEATURE_SETS, k)
8 if is_valid_subset(subset, FEATURE_MANIFEST):
9 return subset
10 raise RuntimeError("cannot sample a valid feature subset")
11
12param_space = {
13 "feature_subset": tune.sample_from(sample_valid_subset),
14 "learning_rate": tune.loguniform(1e-3, 1e-1),
15 "num_leaves": tune.choice([31, 63, 127]),
16}
我的实际建议:
- 先用 Ray Tasks 做单特征集粗筛,把 100 压到 30-50。
- 用 beam / add-drop-swap 局部搜索找特征组合,每轮并行评估邻居。
- 只在最后用 Ray Tune + Optuna 搜模型超参,必要时把 Top-K 特征子集作为一个
feature_subset_id参数一起搜。 - 最终决策看 Pareto Front:不要只看最高 AUC,还要看特征集数量、列数、推理成本、换手率、跨年份稳定性。
- 最后必须独立 walk-forward 复验:Tune 过程中用过的验证集不能再拿来证明模型有效。
这套方案更工程化。Ray 不是在 100 个特征集里"自动发现真理”,它负责把大量候选评估并行跑完;真正降低搜索空间的是你的约束、粗筛、邻域搜索和最终复验。
我个人正在搭的方向是把"特征 + 标签 + CV"三件事都抽象成 Ray Actor,trial 启动时只传一个 config dict,Actor 内部根据 config 拉对应版本的特征、计算对应标签、用对应 CV 切分。这样把 IO 从 trial 里彻底拆出去,单 trial 时间能从分钟降到秒。
这部分代码本文没展开,留到后续单写一篇。这里只是想让你看到:第六章那个 5 分钟的 pipeline 不是终点,它只是搭出了一个能让"全自动 Meta 模型搜索"成为可能的底座。
再往前一步:deadline-aware 调度(HyperSched 思路)
上面那个流水线还有个隐藏假设——“跑多久都行”。但量化研究里一个非常常见的约束是"明早开盘前要给出最优模型":
1给定:
2 - K = 11000+ 个候选 trial
3 - N = 10 个 CPU 核(或者 32 核的 EC2 实例)
4 - T = 12 小时(从现在到开盘)
5
6求: 在 T 时间内能拿到的最高 AUC(或夏普)模型
这个问题不是普通超参搜索——传统 ASHA/PBT 只关心"用最少的资源找到最优",不关心"时间到了必须停"。Ray 社区有一篇 SOCC'19 的论文 HyperSched 正是讲这个:根据剩余时间动态调整每个 trial 的资源分配,差的 trial 早杀,好的 trial 在 deadline 之前能多多跑几轮。
落到本文场景的对应:
- 把
tune.run(num_samples=11000)套上一个time_budget_s=43200(12 小时) - 调度器从 ASHA 换成时间感知版(社区有几个非官方实现,或者自己包一层 stop_criteria)
- Tuner 在 deadline 临近时停止派新 trial,把所有资源汇集给 top-K 在跑的,让它们尽可能多训几个 epoch
- 时间一到,自动
tuner.fit().get_best_result(),输出能赶上开盘的最优模型
这是 Ray 在量化里的下一阶段形态:把"模型质量 vs 截止时间"显式建模成调度约束,让 Ray 替你做"今天先用 8 小时找到能上线的,剩下 4 小时再去探索更激进的方案"这类决策。这部分目前还停留在研究层面,没有生产级开箱即用方案,但是值得提前埋一颗种子。
七、常见坑与调优技巧
下面这些坑在第五章(合成数据 LightGBM)和第六章(Kronos Meta 模型)里都可能遇到,整理出来当 cheat sheet 看。
7.1 Object Store 内存爆了
1ObjectStoreFullError: Object store is full
典型原因:你在循环里 ray.put(),结果 Ray 把每个对象都存了一份。
解决:
- 大对象只
ray.put一次,传ObjectRef给所有任务 - 用
ray.data自动分片,而不是整块 DataFrame - 提高 Object Store 大小:
ray.init(object_store_memory=20 * 1024**3)
7.2 LightGBM 线程数和 Ray 资源冲突
LightGBM 默认会用所有 CPU 核。如果你给一个任务分了 num_cpus=2,但 LightGBM 还在用 16 个线程,就会出现线程争抢,性能反而更差。
解决:参数里加 num_threads=2,和 num_cpus 对齐。
7.3 Dashboard 看不到 Trial 进度
tune.report() 是 Tune 唯一的进度信号。如果你的训练函数从头到尾没调用 tune.report,Dashboard 上就是空的,ASHA 也没法工作。
解决:用 LightGBM 的 callback 在每轮 boost 后上报指标。
7.4 Worker 反复重启
通常是因为 Worker 进程内存超限被 OOMKill。
解决:
- 在 Ray 仪表盘看每个 Worker 的内存曲线
- 减小
bagging_fraction、feature_fraction,降低 LightGBM 内存 - 给 Worker 显式分配
memory资源:@ray.remote(memory=4*1024**3)
7.5 多机训练时的数据本地化
跨机器拉数据走网络,会比本地慢很多。
解决:把训练数据放到所有节点都能访问的位置(NFS、S3、HDFS),或者用 ray.data 让它自动分片到各节点。
八、Ray vs 其他方案
先说结论:本文里所有的并行场景(按文件并行、按窗口并行、超参搜索),multiprocessing、joblib、Optuna 单机其实都能覆盖。Ray 不是唯一选择,下面这张表纯粹是经验感受,没做严格 benchmark:
| 方案 | 上手成本 | 灵活性 | 我会在什么时候选它 |
|---|---|---|---|
| multiprocessing / joblib | 低 | 低 | 单机、任务彼此独立、只需要"撒出去并发跑" |
| Optuna | 低 | 中 | 只做超参搜索,不需要复杂任务编排 |
| Spark | 中 | 中 | 数据量真的大到要分布式 ETL / SQL |
| Dask | 中 | 中 | 想保留 NumPy / Pandas API,做 out-of-core 计算 |
| Ray | 中 | 高 | 需要 Task + Actor + Tune + Train + Serve 配合,或迁移到多机 |
| MPI / Horovod | 高 | 低 | 真分布式 DNN 同步训练 |
Ray 真正值得选的标志是这几个之一:
- 已经在用 Ray Tune 搜超参,想顺手把数据预处理也用 Ray Tasks 写
- 需要长寿命 stateful 服务(Actor)+ 一次性算子(Task)混合调度
- 要从单机平滑过渡到多机集群,不想重写代码
- 想用 Ray Serve 做在线推理,复用同一套训练时的 ObjectRef
如果你只是想"把几个窗口并行跑一下",joblib.Parallel(n_jobs=10) 一行代码也搞定,不一定非要 Ray。本文选 Ray 是因为它能从 Tasks 走到 Tune 再走到 Train,一套 API 通到底,对量化研究这种"实验快速迭代 → 模型上线"的全流程更顺。
8.1 ML 全生命周期里 Ray 和谁竞争 / 谁互补
光说"通用"还是太抽象。下面这张表把 ML 全生命周期拆开,标出 Ray 和每个阶段里的现成框架是替代关系还是共存关系:
| 阶段 | 现成框架 | Ray 是替代还是协同 |
|---|---|---|
| 数据处理 / ETL | Spark、Hadoop、Flink | 协同。大规模 ETL 还是用 Spark,Ray 里读小批量训练数据用 ray.data |
| 离线训练(数据并行) | Horovod、Distributed TF、传统 Parameter Server | 替代。ray.train + TorchTrainer / LightGBMTrainer 替这一层;要兼容老栈也可在 Ray 里直接拉 Horovod |
| 超参搜索 | Vizier、Optuna 单机、各厂内部系统 | 替代。ray.tune 把 Vizier-style 服务 + 分布式调度合到一套 API;Optuna 可以作为 OptunaSearch 接进 Tune |
| 强化学习 | OpenAI Baselines、RLlab、Coach、ChainerRL | 替代。Ray 自己的 RLlib 几乎是开源 RL 事实标准 |
| 在线推理 / 模型服务 | Clipper、TF Serving、Triton | 协同 / 可替代。简单场景 ray.serve 够用;GPU 重负载或多模型路由仍可用 Triton,Ray 负责前置编排 |
| 流处理 | Flink、Kafka Streams | 协同。流处理本身不是 Ray 强项,但用 Actor 做事件驱动微批处理是可行的 |
读这张表的正确姿势:Ray 不是要把上面每个格子都吃掉。它的价值是让你在同一个进程模型 + 同一份 ObjectRef + 同一套调度器里把数据 → 训练 → 调参 → 推理串起来,避免每跨一格就要换栈、换协议、换运维。
对量化研究这种"每天要把新因子塞进特征池 → 跑超参 → 模型对比 → 出实盘信号"的工作流,跨阶段切换的摩擦成本远比单阶段绝对性能更值得优化——这是我个人选 Ray 的最大理由。
九、小结
我们走了两个例子:
- 第五章:合成数据 + 经典选股 LightGBM,4 个滚动窗口从 327s 串行压到 247s(Ray Tasks,1.32x);同样的 Tune 思路在重负载下能拿到 15.12x(见 6.6 节)
- 第六章:本机 Kronos Meta 模型,50 文件子集端到端从 ~20 min 压到 ~1.7 min(~12x),外推全量 573 文件大致是 3.8h → 20min
两个例子的"形状"是一样的:
graph LR
A[Parquet 数据] --> B[ray.data 并行 IO]
B --> C[ray.remote 并行算特征]
C --> D[ray.tune 搜超参]
D --> E[并行 K 折 CV]
E --> F[最终模型]
style A fill:#fed
style F fill:#dfe
记住三句话:
- 架构上:Ray = GCS + Raylet + Object Store + Worker,Driver 通过 ObjectRef 操控一切
- API 上:Task 是函数,Actor 是对象,Object 是数据,三件事而已
- 加速上:Ray Tasks 解决"并行做相同的事",Ray Tune 解决"并行搜超参",Ray Train 解决"单模型太大"
最后两个建议:
- 别一上来就上集群。先在单机用
@ray.remote把代码改顺,验证逻辑正确,再考虑横向扩展。Ray 最大的好处不是它能跑多大,而是它让你从单机平滑过渡到集群时,几乎不用改业务代码 - 资源账要算清楚。trainable / fold task / LightGBM 线程数三层都会消耗 CPU,加起来不能超过物理核。第六章那个 Tune 死锁就是不算账的代价